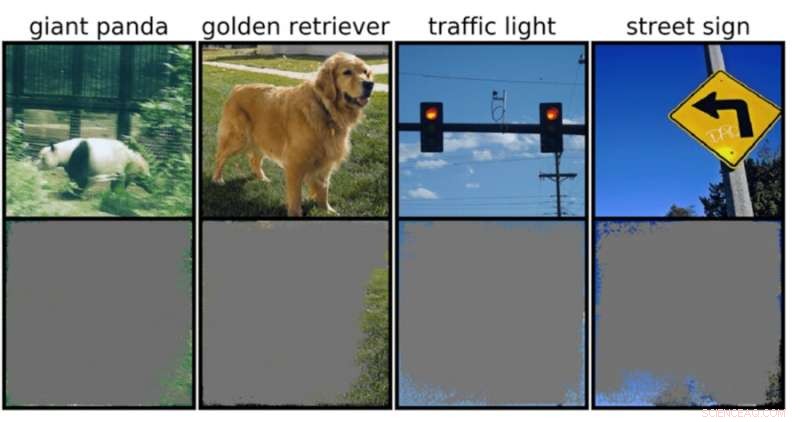
Un classificatore di immagini profonde può determinare classi di immagini con una sicurezza superiore al 90% utilizzando principalmente i bordi dell'immagine, anziché un oggetto stesso. Credito:Rachel Gordon
Nonostante tutto ciò che le reti neurali possono realizzare, non capiamo ancora come funzionano. Certo, possiamo programmarli per imparare, ma dare un senso al processo decisionale di una macchina rimane molto simile a un puzzle di fantasia con uno schema vertiginoso e complesso in cui molti pezzi integrali devono ancora essere montati.
Se un modello stesse tentando di classificare un'immagine di detto puzzle, ad esempio, potrebbe incontrare noti, ma fastidiosi attacchi del contraddittorio, o anche dati più comuni o problemi di elaborazione. Ma un nuovo, più sottile tipo di fallimento recentemente identificato dagli scienziati del MIT è un altro motivo di preoccupazione:la "sovrainterpretazione", in cui gli algoritmi fanno previsioni sicure basate su dettagli che non hanno senso per gli esseri umani, come schemi casuali o bordi dell'immagine.
Ciò potrebbe essere particolarmente preoccupante per gli ambienti ad alto rischio, come le decisioni in una frazione di secondo per le auto a guida autonoma e la diagnostica medica per le malattie che richiedono un'attenzione più immediata. I veicoli autonomi, in particolare, fanno molto affidamento su sistemi in grado di comprendere accuratamente l'ambiente circostante e quindi prendere decisioni rapide e sicure. La rete ha utilizzato sfondi, bordi o particolari schemi del cielo per classificare i semafori e i segnali stradali, indipendentemente da cos'altro c'era nell'immagine.
Il team ha scoperto che le reti neurali addestrate su set di dati popolari come CIFAR-10 e ImageNet soffrivano di sovrainterpretazione. I modelli addestrati su CIFAR-10, ad esempio, hanno fatto previsioni sicure anche quando mancava il 95% delle immagini di input e il resto non ha senso per gli esseri umani.
"La sovrainterpretazione è un problema del set di dati causato da questi segnali senza senso nei set di dati. Non solo queste immagini ad alta affidabilità non sono riconoscibili, ma contengono meno del 10 percento dell'immagine originale in aree non importanti, come i bordi. Abbiamo scoperto che queste immagini erano privi di significato per gli esseri umani, ma i modelli possono ancora classificarli con grande sicurezza", afferma Brandon Carter, MIT Computer Science and Artificial Intelligence Laboratory Ph.D. studente e autore principale di un articolo sulla ricerca.
I classificatori di immagini profonde sono ampiamente utilizzati. Oltre alla diagnosi medica e al potenziamento della tecnologia dei veicoli autonomi, ci sono casi d'uso in sicurezza, giochi e persino un'app che ti dice se qualcosa è o non è un hot dog, perché a volte abbiamo bisogno di rassicurazioni. La tecnologia in discussione funziona elaborando singoli pixel da tonnellate di immagini pre-etichettate affinché la rete possa "imparare".
La classificazione delle immagini è difficile, perché i modelli di apprendimento automatico hanno la capacità di agganciarsi a questi segnali sottili senza senso. Quindi, quando i classificatori di immagini vengono addestrati su set di dati come ImageNet, possono fare previsioni apparentemente affidabili basate su tali segnali.
Sebbene questi segnali privi di senso possano portare alla fragilità del modello nel mondo reale, i segnali sono effettivamente validi nei set di dati, il che significa che non è possibile diagnosticare un'interpretazione eccessiva utilizzando metodi di valutazione tipici basati su tale accuratezza.
Per trovare la motivazione per la previsione del modello su un input particolare, i metodi nel presente studio iniziano con l'immagine completa e si chiedono ripetutamente, cosa posso rimuovere da questa immagine? In sostanza, continua a nascondere l'immagine, finché non ti rimane il pezzo più piccolo che prende ancora una decisione sicura.
A tal fine, potrebbe anche essere possibile utilizzare questi metodi come tipo di criterio di convalida. Ad esempio, se si dispone di un'auto a guida autonoma che utilizza un metodo di apprendimento automatico addestrato per il riconoscimento dei segnali di stop, è possibile testare tale metodo identificando il sottoinsieme di input più piccolo che costituisce un segnale di stop. Se consiste in un ramo di un albero, in una particolare ora del giorno o in qualcosa che non è un segnale di stop, potresti temere che l'auto possa fermarsi in un luogo in cui non dovrebbe.
Sebbene possa sembrare che il modello sia il probabile colpevole qui, è più probabile che la colpa sia dei set di dati. "C'è la domanda su come possiamo modificare i set di dati in modo da consentire ai modelli di essere addestrati per imitare più da vicino il modo in cui un essere umano penserebbe di classificare le immagini e quindi, si spera, generalizzare meglio in questi scenari del mondo reale, come la guida autonoma e diagnosi medica, in modo che i modelli non abbiano questo comportamento senza senso", afferma Carter.
Ciò può significare la creazione di set di dati in ambienti più controllati. Attualmente, sono solo le immagini estratte dai domini pubblici che vengono quindi classificate. Ma se si desidera eseguire l'identificazione degli oggetti, ad esempio, potrebbe essere necessario addestrare i modelli con oggetti con un background non informativo.