Il ritorno della primavera nell’emisfero settentrionale dà il via alla stagione dei tornado. L'imbuto tortuoso di polvere e detriti di un tornado sembra uno spettacolo inconfondibile. Ma quella vista può essere oscurata dal radar, lo strumento dei meteorologi. È difficile sapere esattamente quando si è formato un tornado e anche perché.
Un nuovo set di dati potrebbe contenere risposte. Contiene i risultati radar di migliaia di tornado che hanno colpito gli Stati Uniti negli ultimi 10 anni. Le tempeste che hanno generato tornado sono affiancate da altre forti tempeste, alcune con condizioni quasi identiche, che non si sono mai verificate. I ricercatori del Lincoln Laboratory del MIT che hanno curato il set di dati, chiamato TorNet, lo hanno ora reso open source. Sperano di consentire progressi nell'individuazione di uno dei fenomeni più misteriosi e violenti della natura.
"Molti progressi sono guidati da set di dati di riferimento facilmente disponibili. Ci auguriamo che TorNet getti le basi per algoritmi di apprendimento automatico sia per rilevare che per prevedere i tornado", afferma Mark Veillette, co-investigatore principale del progetto insieme a James Kurdzo. Entrambi i ricercatori lavorano nel gruppo dei sistemi di controllo del traffico aereo.
Insieme al set di dati, il team sta rilasciando modelli addestrati su di esso. I modelli sembrano promettenti per la capacità dell’apprendimento automatico di individuare un tornado. Basandosi su questo lavoro si potrebbero aprire nuove frontiere per i meteorologi, aiutandoli a fornire avvisi più accurati che potrebbero salvare vite umane.
Ogni anno negli Stati Uniti si verificano circa 1.200 tornado, che causano danni economici da milioni a miliardi di dollari e causano in media 71 vittime. L'anno scorso, un tornado dalla durata insolitamente lunga ha ucciso 17 persone e ne ha ferite almeno altre 165 lungo un percorso di 59 miglia nel Mississippi.
Eppure i tornado sono notoriamente difficili da prevedere perché gli scienziati non hanno un quadro chiaro del motivo per cui si formano. "Possiamo vedere due tempeste che sembrano identiche, una produrrà un tornado e l'altra no. Non lo comprendiamo appieno", afferma Kurdzo.
Gli ingredienti di base di un tornado sono i temporali con instabilità causata dal rapido aumento dell'aria calda e dal wind shear che provoca la rotazione. Il radar meteorologico è lo strumento principale utilizzato per monitorare queste condizioni. Ma i tornado si trovano troppo in basso per essere rilevati, anche se moderatamente vicini al radar. Man mano che il raggio radar con un dato angolo di inclinazione si allontana dall'antenna, si alza sopra il suolo, vedendo principalmente i riflessi della pioggia e della grandine trasportati nel "mesociclone", l'ampia corrente ascensionale rotante della tempesta. Un mesociclone non sempre produce un tornado.
Con questa visione limitata, i meteorologi devono decidere se emettere o meno un avviso di tornado. Spesso peccano per eccesso di cautela. Di conseguenza, il tasso di falsi allarmi per gli avvisi di tornado è superiore al 70%.
"Ciò può portare alla sindrome del ragazzo che gridava al lupo", afferma Kurdzo.
Negli ultimi anni, i ricercatori si sono rivolti all’apprendimento automatico per rilevare e prevedere meglio i tornado. Tuttavia, i dati grezzi e i modelli non sono sempre stati accessibili alla comunità più ampia, soffocando il progresso. TorNet sta colmando questa lacuna.
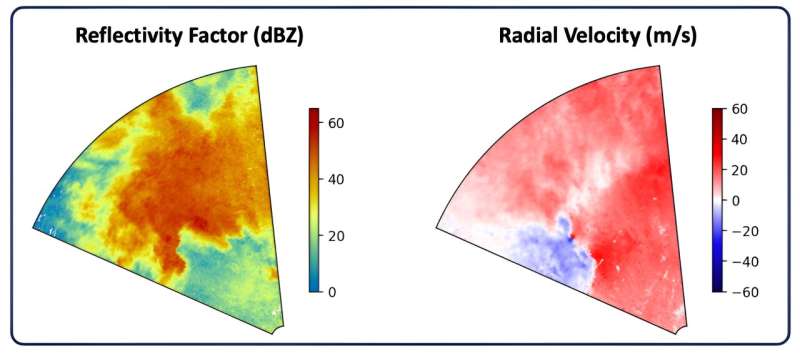
Il set di dati contiene più di 200.000 immagini radar, 13.587 delle quali raffigurano tornado. Il resto delle immagini non sono tornadiche, prese da tempeste di una delle due categorie:tempeste violente selezionate casualmente o tempeste con falso allarme (quelle che hanno portato un meteorologo a emettere un avviso ma che non hanno prodotto un tornado).
Ogni campione di tempesta o tornado comprende due serie di sei immagini radar. I due set corrispondono a diversi angoli di scansione del radar. Le sei immagini ritraggono diversi prodotti di dati radar, come la riflettività (che mostra l'intensità delle precipitazioni) o la velocità radiale (che indica se i venti si stanno avvicinando o allontanando dal radar).
Una sfida nella cura del set di dati è stata innanzitutto trovare i tornado. All’interno del corpus dei dati radar meteorologici, i tornado sono eventi estremamente rari. Il team ha quindi dovuto bilanciare i campioni di tornado con campioni difficili di non tornado. Se il set di dati fosse troppo semplice, ad esempio confrontando i tornado con le tempeste di neve, un algoritmo addestrato sui dati probabilmente classificherebbe eccessivamente le tempeste come tornadi.
"La cosa bella di un vero set di dati di riferimento è che lavoriamo tutti con gli stessi dati, con lo stesso livello di difficoltà e possiamo confrontare i risultati", afferma Veillette. "Rende inoltre la meteorologia più accessibile ai data scientist e viceversa. Diventa più facile per queste due parti lavorare su un problema comune."
Entrambi i ricercatori rappresentano il progresso che può derivare dalla collaborazione incrociata. Veillette è un matematico e sviluppatore di algoritmi da tempo affascinato dai tornado. Kurdzo è un meteorologo di formazione ed esperto di elaborazione dei segnali. All'università inseguiva i tornado con radar mobili personalizzati, raccogliendo dati da analizzare in nuovi modi.
"Questo set di dati significa anche che uno studente laureato non deve dedicare un anno o due alla creazione di un set di dati. Può lanciarsi direttamente nella ricerca", afferma Kurdzo.
Utilizzando il set di dati, i ricercatori hanno sviluppato modelli di intelligenza artificiale (AI) di base. Erano particolarmente desiderosi di applicare il deep learning, una forma di apprendimento automatico che eccelle nell’elaborazione dei dati visivi. Di per sé, il deep learning può estrarre caratteristiche (osservazioni chiave che un algoritmo utilizza per prendere una decisione) dalle immagini di un set di dati. Altri approcci al machine learning richiedono che gli esseri umani etichettino prima manualmente le funzionalità.
"Volevamo vedere se il deep learning potesse riscoprire ciò che le persone normalmente cercano nei tornado e persino identificare nuove cose che in genere non vengono cercate dai meteorologi", afferma Veillette.
I risultati sono promettenti. Il loro modello di deep learning ha funzionato in modo simile o migliore di tutti gli algoritmi di rilevamento dei tornado conosciuti in letteratura. L'algoritmo addestrato ha classificato correttamente il 50% dei tornado EF-1 più deboli e oltre l'85% dei tornado classificati EF-2 o superiore, che costituiscono gli eventi più devastanti e costosi di queste tempeste.
Hanno inoltre valutato altri due tipi di modelli di apprendimento automatico e un modello tradizionale con cui effettuare un confronto. Il codice sorgente e i parametri di tutti questi modelli sono disponibili gratuitamente. I modelli e il set di dati sono descritti anche in un articolo presentato a una rivista dell'American Meteorological Society (AMS). Veillette ha presentato questo lavoro all'Assemblea annuale dell'AMS a gennaio.
"Il motivo principale per pubblicare i nostri modelli è che la comunità li migliori e faccia altre grandi cose", afferma Kurdzo. "La soluzione migliore potrebbe essere un modello di deep learning oppure qualcuno potrebbe scoprire che un modello di deep learning non è effettivamente migliore."
TorNet potrebbe essere utile nella comunità meteorologica anche per altri usi, ad esempio per condurre studi di casi su larga scala sulle tempeste. Potrebbe anche essere arricchito con altre fonti di dati, come immagini satellitari o mappe dei fulmini. La fusione di più tipi di dati potrebbe migliorare la precisione dei modelli di machine learning.
Oltre a rilevare i tornado, Kurdzo spera che i modelli possano aiutare a svelare la scienza del motivo per cui si formano.
"Come scienziati, vediamo tutti questi precursori dei tornado:un aumento della rotazione di basso livello, un'eco ad uncino nei dati di riflettività, il piede della fase differenziale specifica (KDP) e gli archi di riflettività differenziale (ZDR). Ma come vanno tutti insieme? E ci sono manifestazioni fisiche di cui non siamo a conoscenza?" chiede.
Ottenere queste risposte potrebbe essere possibile con l’intelligenza artificiale spiegabile. L’intelligenza artificiale spiegabile si riferisce a metodi che consentono a un modello di fornire il proprio ragionamento, in un formato comprensibile agli esseri umani, sul motivo per cui è arrivato a una determinata decisione. In questo caso, queste spiegazioni potrebbero rivelare processi fisici che avvengono prima dei tornado. Questa conoscenza potrebbe aiutare ad addestrare i meteorologi e i modelli a riconoscere i segnali prima.
"Nessuna di queste tecnologie è destinata a sostituire un meteorologo. Ma forse un giorno potrebbe guidare gli occhi dei meteorologi in situazioni complesse e fornire un avviso visivo a un'area in cui si prevede attività tornadica", afferma Kurdzo.
Tale assistenza potrebbe essere particolarmente utile man mano che la tecnologia radar migliora e le reti future diventano potenzialmente più dense. Si prevede che la velocità di aggiornamento dei dati in una rete radar di prossima generazione aumenterà da ogni cinque minuti a circa un minuto, forse più velocemente di quanto i meteorologi possano interpretare le nuove informazioni. Poiché il deep learning può elaborare rapidamente enormi quantità di dati, potrebbe essere adatto per monitorare i ritorni radar in tempo reale, insieme agli esseri umani. I tornado possono formarsi e scomparire in pochi minuti.
Ma il percorso verso un algoritmo operativo è una strada lunga, soprattutto in situazioni critiche per la sicurezza, afferma Veillette. "Penso che la comunità dei meteorologi sia ancora, comprensibilmente, scettica nei confronti del machine learning. Un modo per stabilire fiducia e trasparenza è disporre di set di dati di riferimento pubblici come questo. È un primo passo."
I prossimi passi, spera il team, saranno compiuti da ricercatori di tutto il mondo che saranno ispirati dal set di dati e stimolati a costruire i propri algoritmi. Tali algoritmi a loro volta entreranno nei banchi di prova, dove verranno eventualmente mostrati ai meteorologi, per avviare un processo di transizione verso le operazioni.
Alla fine, il percorso potrebbe ritornare alla fiducia.
"Utilizzando questi strumenti potremmo non ricevere mai più di 10-15 minuti di allarme tornado. Ma se potessimo abbassare il tasso di falsi allarmi, potremmo iniziare a fare progressi con la percezione pubblica", afferma Kurdzo. "Le persone utilizzeranno questi avvertimenti per intraprendere le azioni necessarie per salvare le proprie vite."
Fornito dal Massachusetts Institute of Technology
Questa storia è stata ripubblicata per gentile concessione di MIT News (web.mit.edu/newsoffice/), un popolare sito che copre notizie sulla ricerca, l'innovazione e l'insegnamento del MIT.














