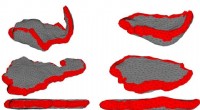
Un nuovo modello sviluppato al MIT recupera dati preziosi persi da immagini e video che sono stati "collassati" in dimensioni inferiori. Può, ad esempio, ricreare video da immagini sfocate o da telecamere che catturano il movimento delle persone dietro gli angoli come linee unidimensionali vaghe. Credito:Massachusetts Institute of Technology
I ricercatori del MIT hanno sviluppato un modello che recupera dati preziosi persi da immagini e video che sono stati "collassati" in dimensioni inferiori.
Il modello potrebbe essere utilizzato per ricreare video da immagini sfocate dal movimento, o da nuovi tipi di fotocamere che catturano il movimento di una persona dietro gli angoli, ma solo come linee unidimensionali vaghe. Sebbene siano necessari ulteriori test, i ricercatori pensano che un giorno questo approccio potrebbe essere utilizzato per convertire immagini mediche 2-D in scansioni corporee 3-D più informative, ma più costose, che potrebbe avvantaggiare l'imaging medico nelle nazioni più povere.
"In tutti questi casi, i dati visivi hanno una dimensione, nel tempo o nello spazio, che è completamente persa, "dice Guha Balakrishnan, un postdoc presso il Computer Science and Artificial Intelligence Laboratory (CSAIL) e primo autore di un articolo che descrive il modello, che verrà presentato alla Conferenza Internazionale sulla Computer Vision della prossima settimana. "Se recuperiamo quella dimensione perduta, può avere molte applicazioni importanti."
I dati visivi acquisiti spesso comprimono i dati di più dimensioni di tempo e spazio in una o due dimensioni, chiamate "proiezioni". raggi X, Per esempio, comprimere i dati tridimensionali sulle strutture anatomiche in un'immagine piatta. O, considera uno scatto a lunga esposizione di stelle che si muovono nel cielo:le stelle, la cui posizione cambia nel tempo, appaiono come strisce sfocate nell'immagine fissa.
Allo stesso modo, "fotocamere d'angolo, " recentemente inventato al MIT, rilevare persone in movimento dietro gli angoli. Questi potrebbero essere utili per, dire, vigili del fuoco che trovano persone negli edifici in fiamme. Ma le telecamere non sono esattamente user-friendly. Attualmente producono solo proiezioni che assomigliano a sfocate, linee ondulate, corrispondente alla traiettoria e alla velocità di una persona.
I ricercatori hanno inventato un modello di "deproiezione visiva" che utilizza una rete neurale per "apprendere" modelli che abbinano le proiezioni a bassa dimensione alle loro immagini e video originali ad alta dimensione. Date le nuove proiezioni, il modello utilizza ciò che ha appreso per ricreare tutti i dati originali da una proiezione.
Negli esperimenti, il modello ha sintetizzato accurati fotogrammi video che mostrano persone che camminano, estraendo informazioni da singoli, linee unidimensionali simili a quelle prodotte dalle telecamere d'angolo. Il modello ha anche recuperato fotogrammi video da singoli, proiezioni sfocate di cifre che si muovono intorno a uno schermo, dal popolare set di dati Moving MNIST.
Insieme a Balakrishnan sul giornale ci sono:Amy Zhao, uno studente laureato presso il Dipartimento di Ingegneria Elettrica e Informatica (EECS) e CSAIL; professori EECS John Guttag, Fredo Durand, e William T. Freeman; e Adriano Dalca, un membro della facoltà di radiologia presso la Harvard Medical School.
Indizi in pixel
Il lavoro è iniziato come un "bello problema di inversione" per ricreare il movimento che causa il motion blur nella fotografia a lunga esposizione, dice Balakrishnan. Nei pixel di una proiezione esistono alcuni indizi sulla sorgente ad alta dimensionalità.
Fotocamere digitali che catturano scatti a lunga esposizione, ad esempio, fondamentalmente aggregherà i fotoni per un periodo di tempo su ciascun pixel. Nel catturare il movimento di un oggetto nel tempo, la fotocamera prenderà il valore medio dei pixel che catturano il movimento. Quindi, applica quei valori medi alle corrispondenti altezze e larghezze di un'immagine fissa, che crea le tipiche strisce sfocate della traiettoria dell'oggetto. Calcolando alcune variazioni di intensità dei pixel, il movimento può teoricamente essere ricreato.
Come hanno capito i ricercatori, questo problema è rilevante in molte aree:raggi X, ad esempio, altezza di cattura, larghezza, e approfondimenti delle strutture anatomiche, ma usano una tecnica simile di media dei pixel per comprimere la profondità in un'immagine 2-D. Telecamere ad angolo—inventate nel 2017 da Freeman, Durand, e altri ricercatori:catturano segnali di luce riflessa intorno a una scena nascosta che trasportano informazioni bidimensionali sulla distanza di una persona da pareti e oggetti. La tecnica della media dei pixel quindi comprime quei dati in un video unidimensionale, in pratica, misurazioni di diverse lunghezze nel tempo in un'unica linea.
I ricercatori hanno costruito un modello generale, basato su una rete neurale convoluzionale (CNN), un modello di apprendimento automatico che è diventato una centrale elettrica per le attività di elaborazione delle immagini, che cattura indizi su qualsiasi dimensione persa in pixel medi.
Sintetizzare i segnali
In allenamento, i ricercatori hanno fornito alla CNN migliaia di coppie di proiezioni e le loro fonti ad alta dimensione, chiamati "segnali". La CNN apprende i modelli di pixel nelle proiezioni che corrispondono a quelli nei segnali. Ad alimentare la CNN c'è un framework chiamato "autoencoder variazionale, " che valuta quanto bene gli output della CNN corrispondano ai suoi input attraverso una certa probabilità statistica. Da ciò, il modello apprende uno "spazio" di tutti i possibili segnali che avrebbero potuto produrre una data proiezione. Questo crea, in sostanza, un tipo di progetto su come passare da una proiezione a tutti i possibili segnali di corrispondenza.
Quando vengono mostrate proiezioni inedite, il modello annota i modelli di pixel e segue i progetti per tutti i possibili segnali che potrebbero aver prodotto quella proiezione. Quindi, sintetizza nuove immagini che combinano tutti i dati della proiezione e tutti i dati del segnale. Questo ricrea il segnale ad alta dimensionalità.
Per un esperimento, i ricercatori hanno raccolto un set di dati di 35 video di 30 persone che camminano in un'area specifica. Hanno compresso tutti i fotogrammi in proiezioni che hanno usato per addestrare e testare il modello. Da una serie di sei proiezioni invisibili, il modello ha ricreato accuratamente 24 fotogrammi dell'andatura della persona, fino alla posizione delle gambe e alle dimensioni della persona mentre si avvicinava o si allontanava dalla telecamera. Il modello sembra imparare, ad esempio, che i pixel che diventano più scuri e più larghi con il tempo probabilmente corrispondono a una persona che si avvicina alla fotocamera.
"È quasi per magia che siamo in grado di recuperare questo dettaglio, " dice Balakrishnan.
I ricercatori non hanno testato il loro modello su immagini mediche. Ma ora stanno collaborando con i colleghi della Cornell University per recuperare informazioni anatomiche 3-D da immagini mediche 2-D, come i raggi X, senza costi aggiuntivi, il che può consentire immagini mediche più dettagliate nelle nazioni più povere. I medici preferiscono principalmente le scansioni 3D, come quelli acquisiti con scansioni TC, perché contengono informazioni mediche molto più utili. Ma le scansioni TC sono generalmente difficili e costose da acquisire.
"Se possiamo convertire i raggi X in scansioni TC, sarebbe in qualche modo rivoluzionario, "Dice Balakrishnan. "Potresti semplicemente prendere una radiografia e farla passare attraverso il nostro algoritmo e vedere tutte le informazioni perse".
Questa storia è stata ripubblicata per gentile concessione di MIT News (web.mit.edu/newsoffice/), un popolare sito che copre notizie sulla ricerca del MIT, innovazione e didattica.