Credito:Petr Kratochvil/dominio pubblico
In un mondo di Deep Fake e di IA del linguaggio naturale fin troppo umano, i ricercatori della Harvard John A. Paulson School of Engineering and Applied Sciences (SEAS) e IBM Research hanno chiesto:esiste un modo migliore per aiutare le persone a rilevare il testo generato dall'intelligenza artificiale?
Quella domanda ha portato Sebastian Gehrmann, un dottorato di ricerca candidato presso SEAS, e Hendrik Strobelt, un ricercatore presso IBM, sviluppare un metodo statistico, insieme a uno strumento interattivo ad accesso aperto, per rilevare il testo generato dall'intelligenza artificiale.
I generatori di linguaggio naturale vengono addestrati su decine di milioni di testi online e imitano il linguaggio umano prevedendo le parole che più spesso si susseguono l'una dopo l'altra. Per esempio, le parole "ho" "am" e "was" sono staticamente più probabili dopo la parola "I".
Usando quell'idea, Gehrmann e Strobelt hanno sviluppato un metodo che, piuttosto che identificare errori nel testo, identifica il testo troppo prevedibile.
"L'idea che abbiamo avuto è che man mano che i modelli migliorano sempre di più, vanno da decisamente peggio degli umani, che è rilevabile, buono quanto o meglio degli umani, che può essere difficile da rilevare con approcci convenzionali, ", ha detto Gehrmann.
"Prima, potresti dire da tutti gli errori che il testo è stato generato dalla macchina, " disse Strobelt. "Ora, non sono più gli errori, ma piuttosto l'uso di parole altamente probabili (e un po' noiose) che richiamano il testo generato dalla macchina. Con questo strumento, gli esseri umani e l'intelligenza artificiale possono lavorare insieme per rilevare il testo falso".
Gehrmann e Strobelt presenteranno la loro ricerca, che è stato co-autore di Alexander Rush, Associato in Informatica presso SEAS, alla conferenza dell'Association for Computational Linguistics (ACL) dal 28 luglio al 2 agosto.
Il metodo di Gehrmann e Strobelt, noto come GLTR, si basa su un modello addestrato su 45 milioni di testi da siti Web:la versione pubblica del modello OpenAI, GPT-2. Poiché utilizza GPT-2 per rilevare il testo generato, GLTR funziona meglio contro GPT-2, ma va bene anche contro altri modelli.
Ecco come funziona:
Se inserisci un passaggio di testo nello strumento, evidenzia il testo in verde, giallo, rosso o viola, ogni colore indica la prevedibilità della parola nel contesto della parola che lo precede. Verde significa che la parola era molto prevedibile, giallo, moderatamente prevedibile, il rosso non è molto prevedibile e il viola significa che il modello non avrebbe affatto previsto la parola.
Quindi un paragrafo di testo generato da GPT-2 sarà simile a questo:

Credito:Università di Harvard
Per confrontare, questo è un vero New York Times articolo:
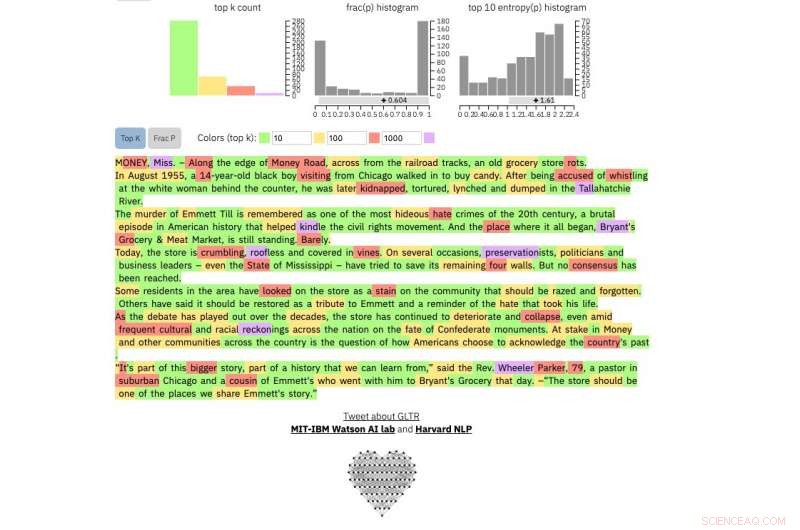
Credito:Università di Harvard
E questo è un estratto da probabilmente il testo umano più imprevedibile mai scritto, di James Joyce Finnegans Wake :
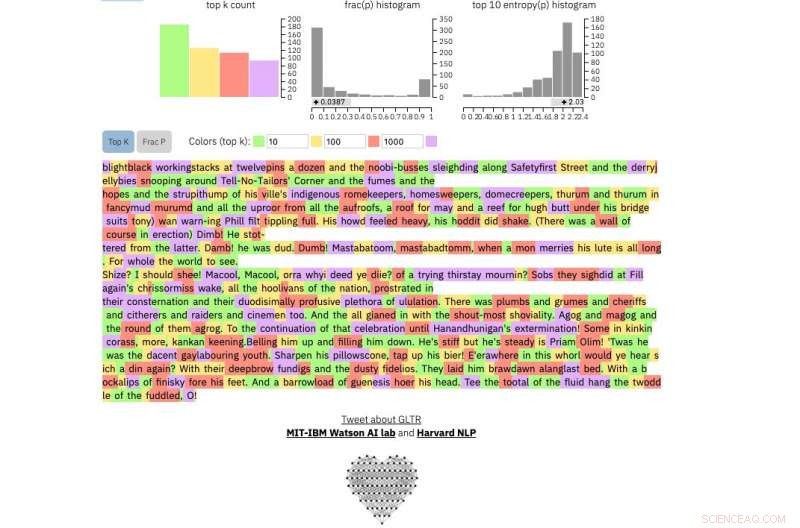
Credito:Università di Harvard
Il metodo non ha lo scopo di sostituire gli umani nell'identificazione di testi falsi, ma piuttosto di supportare l'intuizione e la comprensione umana. I ricercatori hanno testato il modello con un gruppo di studenti universitari in una classe di informatica SEAS.
Senza il modello, gli studenti sono stati in grado di identificare circa il 50 percento del testo generato dall'intelligenza artificiale. Con la sovrapposizione di colori, gli studenti sono stati in grado di identificare il 72 per cento.
Gehrmann e Strobelt affermano che con un po' di allenamento ed esperienza con il programma, il numero potrebbe migliorare ulteriormente.
"Il nostro obiettivo è creare sistemi di collaborazione umana e di intelligenza artificiale, " ha detto Gehrmann. "Questa ricerca è mirata a fornire agli esseri umani maggiori informazioni in modo che possano prendere una decisione informata su ciò che è reale e ciò che è falso".