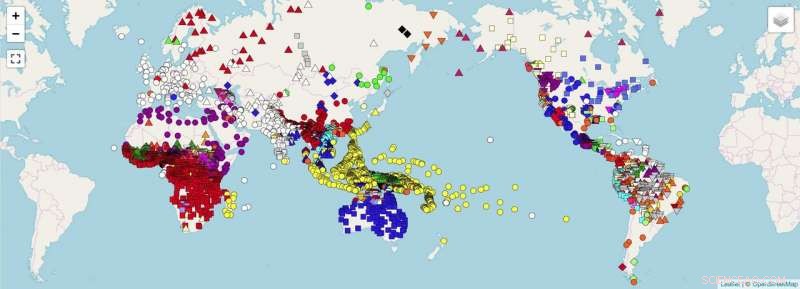
Una mappa del mondo che mostra i punti dati, per i quali i ricercatori intendono raccogliere dati unificati (ad es. dati direttamente confrontabili) utilizzando le linee guida fornite nel documento. Credito:OpenStreetMap. Forkel et al. 2018. Formati di dati interlinguistici, promuovere la condivisione e il riutilizzo dei dati nella linguistica comparata. Dati scientifici .
Un team internazionale di ricercatori, membri della Cross-Linguistic Data Formats Initiative (CLDF) guidata dal Max Planck Institute for the Science of Human History, ha proposto nuove linee guida sui formati di dati interlinguistici al fine di facilitare la condivisione e il confronto dei dati tra il numero crescente di grandi banche dati linguistiche in tutto il mondo. Questo formato fornisce un pacchetto software, un'ontologia di base ed esempi di utilizzo.
Esiste un numero crescente di banche dati linguistiche in tutto il mondo, aumentando la possibilità di una vasta rete per potenziali studi comparativi. Però, questi database sono generalmente creati indipendentemente l'uno dall'altro, e spesso hanno un focus unico e ristretto. Ciò significa che i formati utilizzati per la codifica dei dati sono spesso diversi, creando difficoltà nel confrontare i dati tra i database.
La Cross-Linguistic Data Formats Initiative (CLDF) è uno sforzo per risolvere questi problemi. In un articolo pubblicato su Dati scientifici , il CLDF definisce le linee guida proposte per un formato standardizzato per le banche dati linguistiche, e fornisce anche un pacchetto software, un'ontologia di base ed esempi di utilizzo delle migliori pratiche. L'obiettivo di questo sforzo è facilitare la condivisione e il riutilizzo dei dati nella linguistica comparata.
Il CLDF fornisce un modello di dati alla base delle sue raccomandazioni che mira ad essere semplice, ma espressivo, e si basa sul modello di dati precedentemente sviluppato per il progetto Cross-Linguistic Data. Questo modello ha quattro entità principali:(a) lingue; (b) parametri; (c) valori; e (d) fonti. Nel modello, ogni valore è relativo ad un parametro e ad una lingua, e può essere basato su più fonti. Ci sono inoltre riferimenti per fonti, e i riferimenti possono anche avere contesti (che, Per esempio, per i riferimenti stampati sarebbero i numeri di pagina).
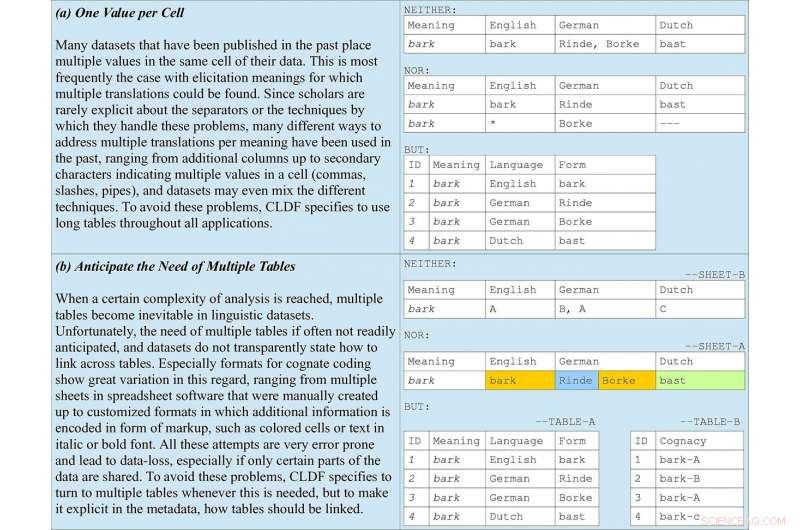
Regole di base della codifica dei dati incluse nelle linee guida, prendendo come esempio la codifica affine negli elenchi di parole. (a) illustra perché le tabelle lunghe dovrebbero essere preferite in tutte le applicazioni. (b) sottolinea l'importanza di anticipare più tabelle insieme a metadati che indicano come dovrebbero essere collegate. Credito:Forkel et al. 2018. Formati di dati interlinguistici, promuovere la condivisione e il riutilizzo dei dati nella linguistica comparata. Dati scientifici .
Il modello di dati CLDF è un formato di pacchetto in cui un set di dati sarebbe costituito da un insieme di file di dati contenenti tabelle, e un file descrittivo che definisce le relazioni tra le tabelle. Ogni tipo di dati linguistici avrebbe un modulo CLDF e componenti aggiuntivi, quali sarebbero gli aspetti dei dati nel modulo che ricorrono su più tipi di dati. I moduli CLDF conterrebbero anche termini dell'ontologia CLDF. L'ontologia è un elenco di vocaboli che rappresentano oggetti e proprietà con semantica ben nota nella linguistica comparata. Ciò consente agli utenti di fare riferimento a questi termini in modo uniforme.
Un pacchetto software per consentire la convalida e la manipolazione
Le specifiche CLDF utilizzano formati di file comuni, come CSV, JSON e BibTeX, ampiamente supportati, con l'obiettivo che questi file possano essere facilmente letti e scritti su molte piattaforme. Ancora più importante, il formato standardizzato consentirà ai ricercatori senza competenze di programmazione di accedere e manipolare i dati con strumenti preesistenti, per evitare di limitare il pacchetto solo ai ricercatori con competenze di programmazione sufficienti per creare i propri strumenti. Per facilitare questo, il CLDF ha creato un repository "ricettario" per gli script da utilizzare con le specifiche CLDF.
"Vogliamo consentire l'accesso a questi dati e la possibilità di confrontarli con il maggior numero possibile di ricercatori, " dice Johann-Mattis List del Max Planck Institute for the Science of Human History. Robert Forkel, una delle forze trainanti dell'iniziativa CLDF, rileva inoltre che il formato CLDF non si limita ai soli dati linguistici, ma può anche incorporare banche dati di dati culturali e geografici, Per esempio. "CLDF può facilitare drasticamente la verifica di domande riguardanti l'interazione tra lingua, culturale, e fattori ambientali nell'evoluzione linguistica e culturale."