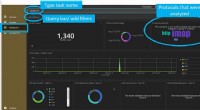
Set di immagini non curato prodotto dal generatore basato sullo stile (config F) con il set di dati FFHQ. Attestazione:arXiv:1812.04948 [cs.NE]
Un nuovo tipo di approccio alla rete avversativa generativa fa grattare la testa agli osservatori della tecnologia:come possono le immagini essere false e tuttavia sembrare così reali?
"Abbiamo creato un nuovo generatore che impara automaticamente a separare diversi aspetti delle immagini senza alcuna supervisione umana, " hanno detto i ricercatori in un video. Hanno affermato nel loro articolo, "La nuova architettura porta a un apprendimento automatico, separazione non supervisionata di attributi di alto livello."
Far sembrare reali le immagini false è uno sforzo artistico che non è affatto nuovo, ma questi tre ricercatori hanno portato lo sforzo al livello successivo.
Hanno spiegato la loro tecnica nella loro carta, "Un'architettura generatore basata sullo stile per reti generative contraddittorie". Il documento è su arXiv e ha attirato molta attenzione.
Stephen Johnson in Pensa in grande ha detto che i risultati sono stati "piuttosto sorprendenti". Will Knight in Revisione della tecnologia del MIT detto ciò che stiamo guardando costituisce "sbalorditivo, realismo quasi inquietante."
I ricercatori, Tero Karras, Samuli Laine, e Timo Aila, sono di Nvidia. Il loro approccio si concentra sulla costruzione di una rete generativa contraddittoria, o GAN, dove avviene l'apprendimento per generare immagini completamente nuove che imitare l'aspetto di foto reali.
Gli autori hanno affermato che tutte le immagini in questo video sono state prodotte dal loro generatore. "Non sono fotografie di persone reali."
La loro carta, " disse Cavaliere, mostrato come l'approccio può essere utilizzato per giocare, e remixare elementi come razza, Genere, o anche lentiggini.
La salsa magica è il loro generatore basato sullo stile. Pensa in grande ha spiegato questo come una versione modificata della tecnologia convenzionale utilizzata per generare automaticamente le immagini.
La loro tecnologia ti sta rovinando la testa e ha l'ultima risata (o parola, comunque lo guardi).
Tu come umano pensi "immagini". Il generatore, però, pensa "raccolta di stile".

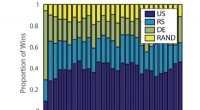
Visualizzare l'effetto degli stili nel generatore facendo in modo che gli stili prodotti da un codice latente (sorgente) sovrascrivano un sottoinsieme degli stili di un altro (destinazione). Attestazione:arXiv:1812.04948 [cs.NE]
Ciascuno stile controlla gli effetti su una scala particolare. Ci sono stili grossolani, stili medi, stili raffinati. (Gli stili grossolani si riferiscono alla posa, capelli, forma del viso; gli stili medi si riferiscono ai tratti del viso; occhi. Gli stili fini si riferiscono alla combinazione di colori.)
sarà cavaliere, nel frattempo, ha fatto alcune osservazioni sui GAN:"I GAN utilizzano due reti neurali duellanti per addestrare un computer ad apprendere la natura di un set di dati abbastanza bene da generare falsi convincenti. Se applicati alle immagini, questo fornisce un modo per generare falsi spesso altamente realistici."
Johnson ha fornito uno sfondo del concetto GAN:
"Nel 2014, un ricercatore di nome Ian Goodfellow e i suoi colleghi hanno scritto un documento che delinea un nuovo concetto di apprendimento automatico chiamato reti generative avversarie. L'idea, in termini semplificati, implica mettere due reti neurali l'una contro l'altra. Uno agisce come un generatore che guarda, dire, immagini di cani e poi fa del suo meglio per creare un'immagine di come si pensa che sia un cane. L'altra rete funge da discriminatore che cerca di distinguere immagini false da quelle reali.
"All'inizio, il generatore potrebbe produrre alcune immagini che non sembrano cani, così il discriminatore li abbatte. Ma il generatore ora sa qualcosa su dove è andato storto, quindi l'immagine successiva che crea è leggermente migliore. Questo processo continua fino a quando, in teoria, il generatore crea una buona immagine di un cane."
Il team di Nvidia ha aggiunto i principi di trasferimento dello stile al mix GAN.
Devin Coldewey in TechCrunch :"Macchine, gatti, paesaggi:tutta questa roba si adatta più o meno allo stesso paradigma del piccolo, caratteristiche medie e grandi che possono essere isolate e riprodotte individualmente."
Da un punto di vista tecnico, il loro lavoro è stato elogiato per i risultati impressionanti nelle immagini di persone che sembrano reali. Da un punto di vista popolare, affilata dal parlare di notizie false, l'avanzamento è visto come pericoloso. "La capacità di generare immagini artificiali realistiche, spesso chiamati deepfake quando le immagini devono sembrare persone riconoscibili, ha destato preoccupazione negli ultimi anni, " ha detto Johnson.
Le pagine del sito di osservazione della tecnologia erano piene di commenti su quanto fosse "inquietante", e alcuni commenti erano semplicemente domande:"Perché lo stiamo facendo?" "Chi lo paga?" "Se non creiamo confini normativi, Penso che la prossima grande battaglia della storia umana sarà combattuta (e forse persa) contro l'IA che creiamo, " ha detto una risposta.
Ciò nonostante, non tutti i commenti riflettevano disagio. Questo è un progresso tecnologico e alcuni commenti hanno sottolineato che le applicazioni potrebbero essere utili in determinati settori. Designer, creatori di agenzie pubblicitarie, e anche i creatori di videogiochi potrebbero utilizzare questa tecnologia per fare un passo avanti.
"Questi volti generati dall'intelligenza artificiale promettono di inaugurare una nuova generazione di persone fotorealistiche nei videogiochi e nei film senza la necessità di attori umani o comparse, " disse HotHardware .
© 2018 Science X Network