Credito:CC0 Dominio Pubblico
La nuova ricerca SFI sfida una concezione popolare di come gli algoritmi di apprendimento automatico "pensano" a determinate attività.
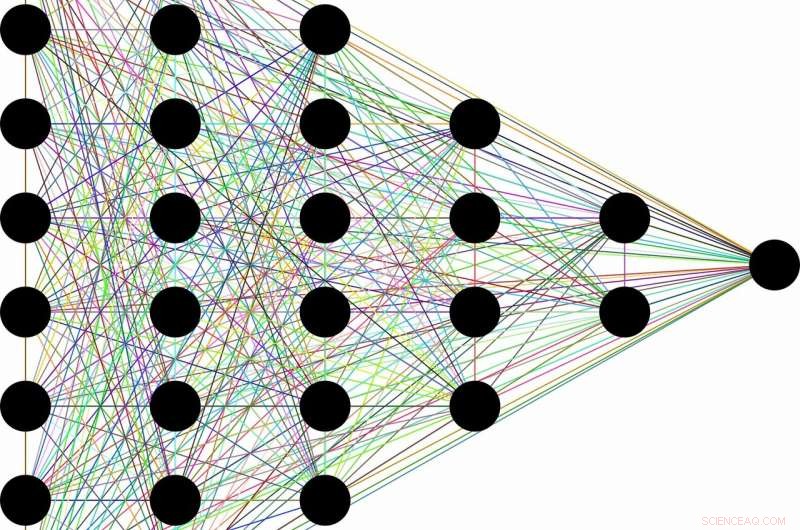
La concezione è più o meno così:a causa della loro capacità di scartare informazioni inutili, una classe di algoritmi di apprendimento automatico chiamati reti neurali profonde può apprendere concetti generali da dati grezzi, come identificare i gatti in genere dopo aver incontrato decine di migliaia di immagini di gatti diversi in situazioni diverse. Si dice che questa capacità apparentemente umana nasca come un sottoprodotto dell'architettura a strati delle reti. I primi livelli codificano l'etichetta "gatto" insieme a tutte le informazioni grezze necessarie per la previsione. I livelli successivi poi comprimono le informazioni, come attraverso un collo di bottiglia. Dati irrilevanti, come il colore del manto del gatto, o il piattino del latte accanto, è dimenticato, lasciando solo le caratteristiche generali. La teoria dell'informazione fornisce limiti su quanto sia ottimale ogni strato, in termini di come può bilanciare le richieste concorrenti di compressione e previsione.
"Molte volte quando hai una rete neurale e impara a mappare i volti sui nomi, o immagini a cifre numeriche, o cose incredibili come il testo francese in testo inglese, ha molti strati nascosti intermedi attraverso i quali scorre l'informazione, "dice Artemy Kolchinsky, un Postdoctoral Fellow SFI e l'autore principale dello studio. "Quindi c'è questa idea di vecchia data che quando gli input grezzi vengono trasformati in queste rappresentazioni intermedie, il sistema sta scambiando la previsione per la compressione, e costruire concetti di livello superiore attraverso questo collo di bottiglia delle informazioni".
Però, Kolchinsky e i suoi collaboratori Brendan Tracey (SFI, MIT) e Steven Van Kuyk (Università di Wellington) hanno scoperto una sorprendente debolezza quando hanno applicato questa spiegazione a problemi di classificazione comuni, dove ogni input ha un output corretto (es. in cui ogni immagine può essere di un gatto o di un cane). In tali casi, hanno scoperto che i classificatori con molti livelli generalmente non rinunciano a qualche previsione per una migliore compressione. Hanno anche scoperto che ci sono molte rappresentazioni "banali" degli input che sono, dal punto di vista della teoria dell'informazione, ottimali in termini di equilibrio tra previsione e compressione.
"Abbiamo scoperto che questa misura del collo di bottiglia delle informazioni non vede la compressione nello stesso modo in cui lo faremmo tu o io. Data la scelta, è altrettanto felice di accomunare "bicchieri da martini" con "Labrador", com'è ammassarli con "flauti di champagne, '", spiega Tracey. "Ciò significa che dovremmo continuare a cercare misure di compressione che si adattino meglio alle nostre nozioni di compressione".
Sebbene l'idea di comprimere gli input possa ancora svolgere un ruolo utile nell'apprendimento automatico, questa ricerca suggerisce che non è sufficiente per valutare le rappresentazioni interne utilizzate dai diversi algoritmi di apprendimento automatico.
Allo stesso tempo, Kolchinsky afferma che il concetto di compromesso tra compressione e previsione sarà ancora valido per compiti meno deterministici, come prevedere il tempo da un set di dati rumorosi. "Non stiamo dicendo che il collo di bottiglia delle informazioni sia inutile per l'apprendimento [machine] supervisionato, " Sottolinea Kolchinsky. "Ciò che mostriamo qui è che si comporta in modo controintuitivo su molti problemi comuni di apprendimento automatico, e questo è qualcosa di cui le persone nella comunità del machine learning dovrebbero essere consapevoli."