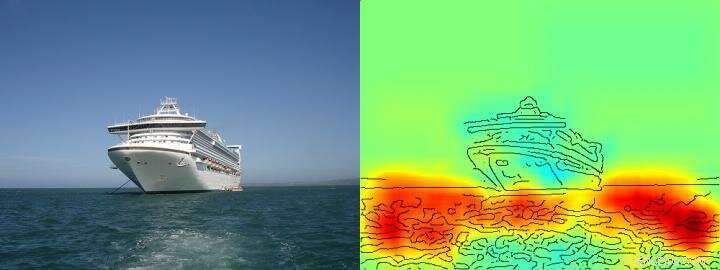
La mappa di calore mostra chiaramente che l'algoritmo prende la decisione nave/non nave sulla base dei pixel che rappresentano l'acqua e non sulla base dei pixel che rappresentano la nave. Credito: Comunicazioni sulla natura , CC BY Lizenz
L'intelligenza artificiale (AI) e le architetture di apprendimento automatico come il deep learning sono diventate parte integrante della nostra vita quotidiana:consentono assistenti vocali digitali o servizi di traduzione, migliorare la diagnostica medica e sono una parte indispensabile delle tecnologie future come la guida autonoma. Basato su una quantità sempre crescente di dati e su nuove potenti architetture di computer, gli algoritmi di apprendimento sembrano avvicinarsi alle capacità umane, a volte addirittura superandoli. Finora, però, spesso rimane sconosciuto agli utenti come esattamente i sistemi di intelligenza artificiale giungano alle loro conclusioni. Perciò, spesso può rimanere poco chiaro se il comportamento decisionale dell'IA sia veramente intelligente o se le procedure abbiano solo un successo medio.
Ricercatori della TU Berlin, Il Fraunhofer Heinrich Hertz Institute HHI e la Singapore University of Technology and Design (SUTD) hanno affrontato questa domanda e hanno fornito uno sguardo al diverso spettro di "intelligenza" osservato negli attuali sistemi di intelligenza artificiale, analizzando specificamente questi sistemi di intelligenza artificiale con una nuova tecnologia che consente l'analisi e la quantificazione automatizzate.
Il prerequisito più importante per questa nuova tecnologia è un metodo sviluppato in precedenza da TU Berlin e Fraunhofer HHI, il cosiddetto algoritmo Layer-wise Relevance Propagation (LRP) che consente di visualizzare in base a quali variabili di input i sistemi di intelligenza artificiale prendono le loro decisioni. Estensione LRP, la nuova analisi di rilevanza spettrale (SpRAy) può identificare e quantificare un ampio spettro di comportamenti decisionali appresi. In questo modo è diventato ora possibile rilevare processi decisionali indesiderati anche in insiemi di dati molto grandi.
Questa cosiddetta "IA spiegabile" è stato uno dei passi più importanti verso un'applicazione pratica dell'IA, secondo il dottor Klaus-Robert Müller, professore di machine learning alla TU Berlin. "Specificamente nella diagnosi medica o nei sistemi critici per la sicurezza, non dovrebbero essere utilizzati sistemi di intelligenza artificiale che impiegano strategie di risoluzione dei problemi traballanti o addirittura ingannevoli."
Utilizzando i loro algoritmi di nuova concezione, i ricercatori sono finalmente in grado di mettere alla prova qualsiasi sistema di IA esistente e ricavarne anche informazioni quantitative:un intero spettro che parte da comportamenti ingenui di problem solving, si osservano strategie di frode fino a soluzioni strategiche "intelligenti" altamente elaborate.
Dottor Wojciech Samek, il leader del gruppo presso Fraunhofer HHI ha dichiarato:"Siamo rimasti molto sorpresi dall'ampia gamma di strategie di risoluzione dei problemi apprese. Anche i moderni sistemi di intelligenza artificiale non hanno sempre trovato una soluzione che appaia significativa dal punto di vista umano, ma a volte usavano le cosiddette strategie di Clever Hans."
L'intelligente Hans era un cavallo che presumibilmente poteva contare ed era considerato una sensazione scientifica durante il 1900. Come si scoprì in seguito, Hans non padroneggiava la matematica, ma in circa il 90% dei casi, è stato in grado di ricavare la risposta corretta dalla reazione dell'interrogante.
Anche il team di Klaus-Robert Müller e Wojciech Samek ha scoperto strategie simili "Clever Hans" in vari sistemi di intelligenza artificiale. Per esempio, un sistema di intelligenza artificiale che qualche anno fa ha vinto diversi concorsi internazionali di classificazione delle immagini ha perseguito una strategia che può essere considerata ingenua dal punto di vista umano. Classificava le immagini principalmente in base al contesto. Le immagini sono state assegnate alla categoria "nave" quando c'era molta acqua nella foto. Altre immagini sono state classificate come "treno" se erano presenti le rotaie. Ancora altre immagini sono state assegnate alla categoria corretta dalla loro filigrana di copyright. Il vero compito, vale a dire per rilevare i concetti di navi o treni, non è stato quindi risolto da questo sistema di intelligenza artificiale, anche se ha effettivamente classificato correttamente la maggior parte delle immagini.
I ricercatori sono stati anche in grado di trovare questi tipi di strategie di risoluzione dei problemi difettose in alcuni degli algoritmi di intelligenza artificiale all'avanguardia, le cosiddette reti neurali profonde, algoritmi che erano stati considerati immuni da tali errori. Queste reti hanno basato le loro decisioni di classificazione in parte su artefatti che sono stati creati durante la preparazione delle immagini e non hanno nulla a che fare con l'effettivo contenuto dell'immagine.
"Tali sistemi di intelligenza artificiale non sono utili nella pratica. Il loro utilizzo nella diagnostica medica o in aree critiche per la sicurezza comporterebbe anche enormi pericoli, " ha affermato Klaus-Robert Müller. "È abbastanza concepibile che circa la metà dei sistemi di intelligenza artificiale attualmente in uso si basino implicitamente o esplicitamente su tali strategie di Clever Hans. È tempo di verificarlo sistematicamente in modo da poter sviluppare sistemi di intelligenza artificiale sicuri".
Con la loro nuova tecnologia, i ricercatori hanno anche identificato i sistemi di intelligenza artificiale che hanno appreso inaspettatamente strategie "intelligenti". Gli esempi includono i sistemi che hanno imparato a giocare ai giochi Atari Breakout e Pinball. "Qui, l'IA ha compreso chiaramente il concetto di gioco, e ha trovato un modo intelligente per raccogliere molti punti in modo mirato e a basso rischio. Il sistema a volte interviene anche in modi che un giocatore reale non farebbe, " disse Wojciech Samek.
"Oltre a comprendere le strategie dell'IA, il nostro lavoro stabilisce l'usabilità dell'IA spiegabile per la progettazione iterativa di set di dati, vale a dire per rimuovere artefatti in un set di dati che indurrebbero un'intelligenza artificiale ad apprendere strategie errate, oltre ad aiutare a decidere quali esempi senza etichetta devono essere annotati e aggiunti in modo che i guasti di un sistema di IA possano essere ridotti, ", ha affermato l'assistente professore di SUTD Alexander Binder.
"La nostra tecnologia automatizzata è open source e disponibile per tutti gli scienziati. Consideriamo il nostro lavoro un primo passo importante per rendere i sistemi di intelligenza artificiale più robusti, spiegabile e sicuro in futuro, e altro dovrà seguire. Questo è un prerequisito essenziale per l'uso generale dell'IA, ", ha detto Klaus-Robert Müller.