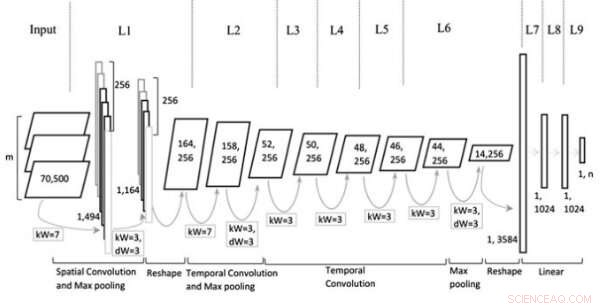
Architettura del modello. Credito:Jin et al. Rivista Wiley Computational Intelligence.
Negli ultimi dieci anni o giù di lì, le reti neurali convoluzionali (CNN) si sono dimostrate molto efficaci nell'affrontare una varietà di compiti, comprese le attività di elaborazione del linguaggio naturale (NLP). La PNL comporta l'uso di tecniche computazionali per analizzare o sintetizzare il linguaggio, sia in forma scritta che orale. I ricercatori hanno applicato con successo le CNN a diversi compiti di PNL, compresa l'analisi semantica, recupero delle query di ricerca e classificazione del testo.
Tipicamente, Le CNN addestrate per le attività di classificazione del testo elaborano le frasi a livello di parola, rappresentare singole parole come vettori. Sebbene questo approccio possa sembrare coerente con il modo in cui gli esseri umani elaborano il linguaggio, studi recenti hanno dimostrato che anche le CNN che elaborano frasi a livello di carattere possono ottenere risultati notevoli.
Un vantaggio chiave delle analisi a livello di carattere è che non richiedono una conoscenza preliminare delle parole. Ciò rende più facile per le CNN adattarsi a lingue diverse e acquisire parole anomale causate da errori di ortografia.
Studi precedenti suggeriscono che diversi livelli di incorporamento del testo (es. parola-, o a livello di documento) sono più efficaci per diversi tipi di attività, ma non c'è ancora una guida chiara su come scegliere l'incorporamento giusto o quando passare a un altro. Con questo in testa, un team di ricercatori della Tianjin Polytechnic University in Cina ha recentemente sviluppato una nuova architettura della CNN basata su tipi di rappresentazione tipicamente utilizzati nelle attività di classificazione del testo.
"Proponiamo una nuova architettura della CNN basata su rappresentazioni multiple per la classificazione del testo costruendo più piani in modo che più informazioni possano essere scaricate nelle reti, come diverse parti di testo ottenute tramite un riconoscitore di entità denominato o strumenti di tagging di parti del discorso, diversi livelli di incorporamento del testo o frasi contestuali, " hanno scritto i ricercatori nel loro articolo.
Il modello multi-rappresentativo della CNN (Mr-CNN) ideato dai ricercatori si basa sul presupposto che tutte le parti del testo scritto (es. verbi, ecc.) svolgono un ruolo chiave nelle attività di classificazione e che i diversi incorporamenti di testo sono più efficaci per scopi diversi. Il loro modello combina due strumenti chiave, il riconoscitore di entità denominata Stanford (NER) e il tagger della parte del discorso (POS). Il primo è un metodo per etichettare i ruoli semantici delle cose nei testi (ad esempio persona, società, eccetera.); quest'ultima è una tecnica utilizzata per assegnare parti di tag vocali a ciascun blocco di testo (ad es. sostantivo o verbo).
I ricercatori hanno utilizzato questi strumenti per pre-elaborare le frasi, ottenendo diversi sottoinsiemi della frase originale, ognuno dei quali contiene specifici tipi di parole nel testo. Hanno quindi utilizzato i sottoinsiemi e la frase completa come rappresentazioni multiple per il loro modello Mr-CNN.
Quando viene valutato su attività di classificazione del testo con testo proveniente da vari set di dati su larga scala e specifici del dominio, il modello Mr-CNN ha raggiunto prestazioni notevoli, con un miglioramento del tasso di errore massimo del 13% su un set di dati e un miglioramento dell'8% su un altro. Ciò suggerisce che più rappresentazioni del testo consentono alla rete di focalizzare in modo adattivo la sua attenzione sulle informazioni più rilevanti, potenziando le sue capacità di classificazione.
"Varie su larga scala, set di dati specifici del dominio sono stati utilizzati per convalidare l'architettura proposta, " hanno scritto i ricercatori. "I compiti analizzati includono la classificazione dei documenti ontologici, categorizzazione di eventi biomedici, e analisi del sentimento, mostrando che le CNN multi-rappresentazionali, che imparano a focalizzare l'attenzione su specifiche rappresentazioni del testo, può ottenere ulteriori miglioramenti in termini di prestazioni rispetto ai modelli di rete neurale profonda all'avanguardia".
Nel loro lavoro futuro, i ricercatori hanno in programma di indagare se le funzionalità a grana fine possono aiutare a prevenire l'overfitting del set di dati di addestramento. Vogliono anche esplorare altri metodi che potrebbero migliorare l'analisi di parti specifiche di frasi, potenzialmente migliorando ulteriormente le prestazioni del modello.
© 2019 Scienza X Rete