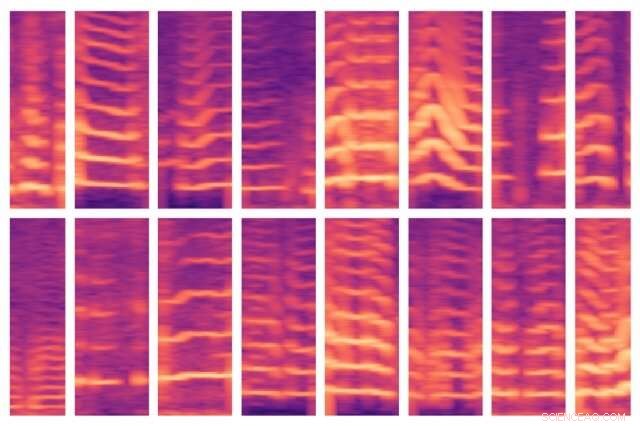
Un nuovo modello sviluppato dal MIT automatizza un passaggio fondamentale nell'utilizzo dell'intelligenza artificiale per il processo decisionale medico, dove gli esperti di solito identificano manualmente le caratteristiche importanti in enormi set di dati dei pazienti. Il modello è stato in grado di identificare automaticamente i modelli vocali di persone con noduli alle corde vocali (mostrati qui) e, a sua volta, usa queste caratteristiche per prevedere quali persone hanno e non hanno il disturbo. Credito:Massachusetts Institute of Technology
Gli scienziati informatici del MIT sperano di accelerare l'uso dell'intelligenza artificiale per migliorare il processo decisionale medico, automatizzando un passaggio chiave che di solito viene eseguito manualmente e che sta diventando sempre più laborioso man mano che determinati set di dati diventano sempre più grandi.
Il campo dell'analisi predittiva è sempre più promettente per aiutare i medici a diagnosticare e curare i pazienti. I modelli di apprendimento automatico possono essere addestrati per trovare modelli nei dati dei pazienti per aiutare nella cura della sepsi, progettare regimi chemioterapici più sicuri, e prevedere il rischio di un paziente di avere il cancro al seno o di morire in terapia intensiva, per citare solo alcuni esempi.
Tipicamente, i set di dati di addestramento sono costituiti da molti soggetti malati e sani, ma con relativamente pochi dati per ogni soggetto. Gli esperti devono quindi trovare solo quegli aspetti, o "caratteristiche", nei set di dati che saranno importanti per fare previsioni.
Questa "ingegneria delle funzionalità" può essere un processo laborioso e costoso. Ma sta diventando ancora più difficile con l'aumento dei sensori indossabili, perché i ricercatori possono monitorare più facilmente i dati biometrici dei pazienti per lunghi periodi, monitoraggio dei modelli di sonno, andatura, e attività vocale, Per esempio. Dopo solo una settimana di monitoraggio, gli esperti potrebbero avere diversi miliardi di campioni di dati per ogni argomento.
In un documento presentato alla conferenza Machine Learning for Healthcare questa settimana, I ricercatori del MIT dimostrano un modello che apprende automaticamente le caratteristiche predittive dei disturbi delle corde vocali. Le caratteristiche provengono da un dataset di circa 100 soggetti, ciascuno con circa una settimana di dati di monitoraggio vocale e diversi miliardi di campioni, in altre parole, un numero limitato di soggetti e una grande quantità di dati per soggetto. Il set di dati contiene segnali catturati da un piccolo sensore accelerometro montato sul collo dei soggetti.
Negli esperimenti, il modello ha utilizzato le caratteristiche estratte automaticamente da questi dati per classificare, con elevata precisione, pazienti con e senza noduli alle corde vocali. Queste sono lesioni che si sviluppano nella laringe, spesso a causa di schemi di uso improprio della voce come cantare a squarciagola o urlare. È importante sottolineare che il modello ha svolto questo compito senza un ampio set di dati etichettati a mano.
"Sta diventando sempre più facile raccogliere set di dati di serie temporali lunghe. Ma ci sono medici che hanno bisogno di applicare le loro conoscenze all'etichettatura del set di dati, " dice l'autore principale Jose Javier Gonzalez Ortiz, un dottorato di ricerca studente del MIT Computer Science and Artificial Intelligence Laboratory (CSAIL). "Vogliamo rimuovere quella parte manuale per gli esperti e trasferire tutta la progettazione delle funzionalità su un modello di apprendimento automatico".
Il modello può essere adattato per apprendere modelli di qualsiasi malattia o condizione. Ma la capacità di rilevare i modelli quotidiani di utilizzo della voce associati ai noduli delle corde vocali è un passo importante nello sviluppo di metodi migliori per prevenire, diagnosticare, e curare il disturbo, dicono i ricercatori. Ciò potrebbe includere la progettazione di nuovi modi per identificare e avvisare le persone di comportamenti vocali potenzialmente dannosi.
Insieme a Gonzalez Ortiz sul giornale c'è John Guttag, il Dugald C. Jackson Professor di Informatica e Ingegneria Elettrica e capo del Data Driven Inference Group di CSAIL; Robert Hillman, Jarrad Van Stan, e Daryush Mehta, tutto il Centro per la chirurgia laringea e la riabilitazione vocale del Massachusetts General Hospital; e Marzyeh Ghassemi, un assistente professore di informatica e medicina presso l'Università di Toronto.
Apprendimento forzato delle funzioni
Per anni, i ricercatori del MIT hanno lavorato con il Center for Laryngeal Surgery and Voice Rehabilitation per sviluppare e analizzare i dati di un sensore per tenere traccia dell'utilizzo della voce del soggetto durante tutte le ore di veglia. Il sensore è un accelerometro con un nodo che si attacca al collo ed è collegato a uno smartphone. Mentre la persona parla, lo smartphone raccoglie i dati dagli spostamenti nell'accelerometro.
Nel loro lavoro, i ricercatori hanno raccolto una settimana di questi dati, chiamati dati "serie temporali", da 104 soggetti, alla metà dei quali sono stati diagnosticati noduli alle corde vocali. Per ogni paziente, c'era anche un controllo corrispondente, intendendo un soggetto sano di età simile, sesso, occupazione, e altri fattori.
Tradizionalmente, gli esperti dovrebbero identificare manualmente le caratteristiche che possono essere utili per un modello per rilevare varie malattie o condizioni. Ciò aiuta a prevenire un problema di apprendimento automatico comune nell'assistenza sanitaria:il sovradattamento. questo è quando, in allenamento, un modello "memorizza" i dati del soggetto invece di apprendere solo le caratteristiche clinicamente rilevanti. Nella prova, quei modelli spesso non riescono a discernere modelli simili in soggetti inediti.
"Invece di apprendere caratteristiche clinicamente significative, un modello vede i modelli e dice, "Questa è Sara, e so che Sarah è sana, e questo è Pietro, che ha un nodulo alle corde vocali." Quindi, è solo memorizzare modelli di soggetti. Quindi, quando vede i dati di Andrew, che ha un nuovo modello di utilizzo vocale, non riesce a capire se quei modelli corrispondono a una classificazione, "Dice González Ortiz.
La sfida principale, poi, stava prevenendo l'overfitting mentre automatizzava la progettazione manuale delle funzionalità. A quello scopo, i ricercatori hanno costretto il modello ad apprendere le caratteristiche senza informazioni sul soggetto. Per il loro compito, ciò significava catturare tutti i momenti in cui i soggetti parlano e l'intensità delle loro voci.
Mentre il loro modello esegue la scansione dei dati di un soggetto, è programmato per localizzare i segmenti vocali, che costituiscono solo il 10% circa dei dati. Per ciascuna di queste finestre vocali, il modello calcola uno spettrogramma, una rappresentazione visiva dello spettro di frequenze variabili nel tempo, che viene spesso utilizzato per le attività di elaborazione del parlato. Gli spettrogrammi vengono quindi memorizzati come grandi matrici di migliaia di valori.
Ma quelle matrici sono enormi e difficili da elaborare. Così, un codificatore automatico, una rete neurale ottimizzata per generare codifiche di dati efficienti da grandi quantità di dati, comprime prima lo spettrogramma in una codifica di 30 valori. Quindi decomprime quella codifica in uno spettrogramma separato.
Fondamentalmente, il modello deve garantire che lo spettrogramma decompresso assomigli molto all'input dello spettrogramma originale. Così facendo, è costretto ad apprendere la rappresentazione compressa di ogni segmento di spettrogramma in ingresso su tutti i dati delle serie temporali di ciascun soggetto. Le rappresentazioni compresse sono le funzionalità che aiutano a formare i modelli di apprendimento automatico per fare previsioni.
Mappatura delle caratteristiche normali e anormali
In allenamento, il modello impara a mappare quelle caratteristiche su "pazienti" o "controlli". I pazienti avranno più schemi vocali rispetto ai controlli. Nei test su soggetti inediti, il modello condensa allo stesso modo tutti i segmenti dello spettrogramma in un insieme ridotto di caratteristiche. Quindi, è la regola della maggioranza:se il soggetto ha segmenti vocali per lo più anormali, sono classificati come pazienti; se ne hanno per lo più normali, sono classificati come controlli.
Negli esperimenti, il modello è stato eseguito con la stessa precisione dei modelli all'avanguardia che richiedono la progettazione manuale delle funzionalità. È importante sottolineare che il modello dei ricercatori è stato eseguito con precisione sia nella formazione che nei test, indicando che sta imparando modelli clinicamente rilevanti dai dati, informazioni non specifiche del soggetto.
Prossimo, i ricercatori vogliono monitorare come i vari trattamenti, come la chirurgia e la terapia vocale, influenzino il comportamento vocale. Se i comportamenti dei pazienti si spostano da anormali a normali nel tempo, molto probabilmente stanno migliorando. Sperano anche di usare una tecnica simile sui dati dell'elettrocardiogramma, che viene utilizzato per monitorare le funzioni muscolari del cuore.
Questa storia è stata ripubblicata per gentile concessione di MIT News (web.mit.edu/newsoffice/), un popolare sito che copre notizie sulla ricerca del MIT, innovazione e didattica.














