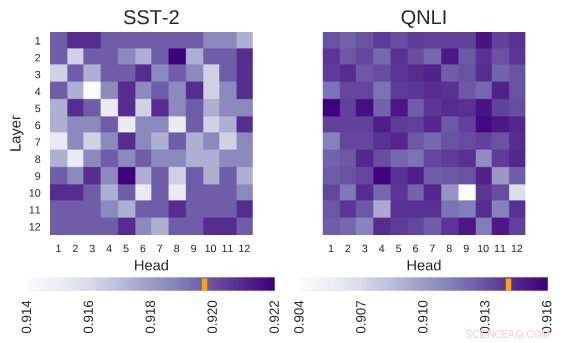
L'architettura BERT indagata ha l'architettura di 12 strati per 12 teste. Ogni cella in questa figura mostra le prestazioni di BERT se la testa corrispondente è spenta. I colori più scuri indicano prestazioni più elevate, e i globuli bianchi indicano le teste senza le quali le prestazioni di BERT diminuiscono. Stanford Sentiment Treebank (SST-2):ci sono più teste che codificano le informazioni necessarie per l'attività. Domanda Natural Language Inference (QNLI):la maggior parte delle testine migliora le prestazioni complessive quando sono spente. Credito:Kovaleva et al.
BERTO, un modello basato su trasformatore caratterizzato da un meccanismo di auto-attenzione unico, ha finora dimostrato di essere una valida alternativa alle reti neurali ricorrenti (RNN) nell'affrontare compiti di elaborazione del linguaggio naturale (NLP). Nonostante i loro vantaggi, finora, pochissimi ricercatori hanno studiato a fondo queste architetture basate su BERT, o hanno cercato di capire le ragioni alla base dell'efficacia del loro meccanismo di auto-attenzione.
Consapevole di questa lacuna in letteratura, i ricercatori del Text Machine Lab for Natural Language Processing dell'Università del Massachusetts Lowell hanno recentemente condotto uno studio sull'interpretazione dell'auto-attenzione, il componente più vitale dei modelli BERT. Il ricercatore principale e l'autore senior di questo studio erano Olga Kovaleva e Anna Rumshisky, rispettivamente. Il loro articolo è stato pre-pubblicato su arXiv e sarà presentato alla conferenza EMNLP 2019, suggerisce che una quantità limitata di modelli di attenzione viene ripetuta tra diversi sottocomponenti BERT, alludendo alla loro eccessiva parametrizzazione.
"BERT è un modello recente che ha fatto un passo avanti nella comunità della PNL, conquistando le classifiche in più attività. Ispirato da questa recente tendenza, eravamo curiosi di indagare come e perché funziona, "Il team di ricercatori ha detto a TechXplore via e-mail. "Speravamo di trovare una correlazione tra l'auto-attenzione, il principale meccanismo alla base del BERT, e relazioni linguisticamente interpretabili all'interno del testo di input dato."
Le architetture basate su BERT hanno una struttura a strati, e ciascuno dei suoi strati è costituito dalle cosiddette "teste". Affinché il modello funzioni, ciascuna di queste teste è addestrata a codificare un tipo specifico di informazioni, contribuendo così a suo modo al modello complessivo. Nel loro studio, i ricercatori hanno analizzato le informazioni codificate da queste singole teste, puntando sia sulla quantità che sulla qualità.
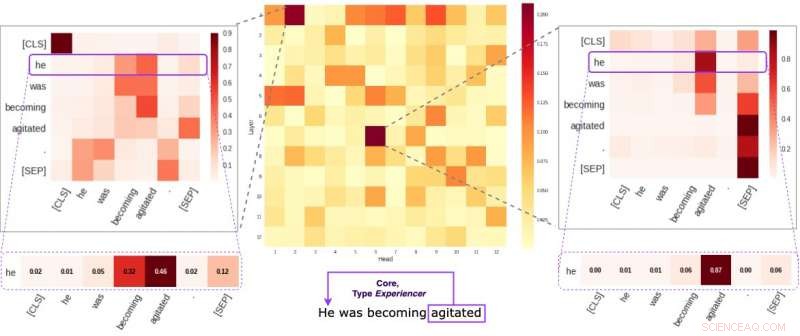
Ogni cella nella figura centrale riflette il modo in cui le singole teste prestano attenzione ai collegamenti semantici principali all'interno di una determinata frase (in media). Abbiamo identificato due teste specifiche che tendono a codificare le informazioni semantiche più delle altre. Le due immagini ai lati dimostrano come queste due teste assegnano pesi alle singole parole all'interno di una frase casuale del nostro dataset. Credito:Kovaleva et al.
"La nostra metodologia si è concentrata sull'esame delle teste individuali e sui modelli di attenzione che hanno prodotto, " hanno spiegato i ricercatori. "Essenzialmente, stavamo cercando di rispondere alla domanda:"Quando BERT codifica una singola parola di una frase, presta attenzione alle altre parole in un modo significativo per gli umani?"
I ricercatori hanno effettuato una serie di esperimenti utilizzando modelli BERT di base preaddestrati e perfezionati. Ciò ha permesso loro di raccogliere numerose interessanti osservazioni relative al meccanismo di auto-attenzione che è alla base delle architetture basate su BERT. Ad esempio, hanno osservato che un insieme limitato di modelli di attenzione viene spesso ripetuto su teste diverse, il che suggerisce che i modelli BERT sono sovra-parametrizzati.
"Abbiamo scoperto che BERT tende a essere parametrizzato in modo eccessivo, e c'è molta ridondanza nelle informazioni che codifica, " hanno detto i ricercatori. "Ciò significa che l'impronta computazionale della formazione di un modello così grande non è ben giustificata".
Un'ulteriore scoperta interessante raccolta dal team di ricercatori dell'Università del Massachusetts Lowell è che a seconda del compito affrontato da un modello BERT, spegnere casualmente alcune delle sue testine può portare a un miglioramento, piuttosto che un declino, nelle prestazioni. Inoltre, i ricercatori non hanno identificato alcun modello linguistico di particolare importanza nel determinare le prestazioni del BERT nelle attività a valle.
"Rendere interpretabile il deep learning è importante sia per la ricerca fondamentale che per quella applicata, e continueremo a lavorare in questa direzione, " hanno detto i ricercatori. "Nuovi modelli basati su BERT sono stati recentemente rilasciati, e abbiamo in programma di estendere la nostra metodologia per indagare anche su di loro".
© 2019 Scienza X Rete