Credito:Gupta et al.
L'apprendimento per rinforzo (RL) è una tecnica di apprendimento automatico ampiamente utilizzata che prevede l'addestramento di agenti o robot di intelligenza artificiale utilizzando un sistema di ricompensa e punizione. Finora, i ricercatori nel campo della robotica hanno applicato principalmente tecniche di RL in compiti che vengono completati in periodi di tempo relativamente brevi, come muoversi in avanti o afferrare oggetti.
Un team di ricercatori di Google e Berkeley AI Research ha recentemente sviluppato un nuovo approccio che combina RL con l'apprendimento per imitazione, un processo chiamato relay policy learning. Questo approccio, introdotto in un documento prepubblicato su arXiv e presentato alla Conference on Robot Learning (CoRL) 2019 a Osaka, può essere utilizzato per addestrare agenti artificiali per affrontare compiti a più stadi e a lungo orizzonte, come attività di manipolazione di oggetti che si estendono su periodi di tempo più lunghi.
"La nostra ricerca ha avuto origine da molti, per lo più senza successo, esperimenti con compiti molto lunghi utilizzando l'apprendimento per rinforzo (RL), "Abhishek Gupta, uno dei ricercatori che ha condotto lo studio, ha detto a TechXplore. "Oggi, RL in robotica è per lo più applicato in compiti che possono essere realizzati in un breve lasso di tempo, come afferrare, spingere oggetti, camminando in avanti, ecc. Mentre queste applicazioni hanno molto valore, il nostro obiettivo era applicare l'apprendimento per rinforzo a compiti che richiedono più sotto-obiettivi e operano su scale temporali molto più lunghe, come apparecchiare la tavola o pulire la cucina."
Prima di iniziare a sviluppare il loro approccio, Gupta e i suoi colleghi hanno esaminato la letteratura precedente per cercare di determinare perché i compiti più lunghi sono particolarmente difficili da affrontare utilizzando le attuali tecniche di RL. Nella loro carta, suggeriscono che ci sono generalmente due ragioni principali per questo.
Primo, è difficile per un robot identificare soluzioni ottimali per risolvere da solo compiti lunghi e complessi. Secondo, è difficile per l'agente affrontare con successo un compito lungo per il quale il feedback viene fornito solo alla fine di una lunga sequenza. Relè l'apprendimento delle politiche, il nuovo approccio all'apprendimento che hanno presentato, è progettato per affrontare a testa alta entrambe queste sfide.
Credito:Gupta et al.
"Per affrontare la sfida di far sì che i robot risolvano da soli compiti a lungo orizzonte, abbiamo deciso di semplificare il problema e utilizzare dimostrazioni fornite dall'uomo, " Ha detto Gupta. "Risolvere compiti lunghi è difficile perché è estremamente difficile che un robot scopra un comportamento interessante da solo:le dimostrazioni fornite dall'uomo possono essere utilizzate come linea guida per cose interessanti da fare in un ambiente".
L'approccio per l'apprendimento dei robot proposto da Gupta e dai suoi colleghi ha due fasi distinte, uno in cui un agente impara imitando gli umani e l'altro basato su RL. Nella fase di apprendimento dell'imitazione, un robot riceve dimostrazioni umane su come completare un'attività e produce politiche gerarchiche basate su obiettivi.
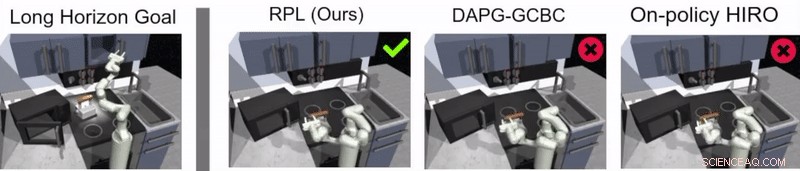
Nel loro studio, i ricercatori hanno usato il loro approccio per addestrare un agente artificiale chiamato Franka su compiti di manipolazione a più stadi e a lungo orizzonte in un ambiente di cucina simulato, che è stato modellato utilizzando la piattaforma di simulazione fisica MuJoCo. Questo ambiente era composto da una cucina con forno a microonde apribile, quattro fuochi da forno, un interruttore della luce del forno, un bollitore, due armadi a battente e un'anta scorrevole.

Credito:Gupta et al.
"È importante che imparare dalle dimostrazioni da solo non è sufficiente per risolvere i compiti impegnativi nel nostro ambiente di cucina simulato, "Karol Hausman, un altro ricercatore coinvolto nello studio, ha detto a TechXplore. "Per migliorare questa soluzione iniziale, permettiamo ai robot di esercitare i compiti da soli per perfezionare ulteriormente i loro comportamenti."
Essenzialmente, utilizzando il metodo di apprendimento delle politiche di collegamento proposto dai ricercatori, un agente inizialmente apprende elaborando dimostrazioni umane su come completare un determinato compito e poi continua ad apprendere da solo tramite RL. Per facilitare il processo di apprendimento delle politiche a lungo termine, il team ha utilizzato un nuovo algoritmo di rietichettatura dei dati che consente a un agente di apprendere politiche gerarchiche basate su obiettivi.
"Per affrontare la sfida del feedback sparso, usiamo una struttura gerarchica per le nostre politiche di controllo:la politica di alto livello propone obiettivi che la politica di basso livello cerca di raggiungere, ad esempio, chiudere un armadio, spegni il fornello, eccetera., " Hausman ha spiegato. "In questo modo, il compito può essere facilmente scomposto in sottoproblemi più piccoli che possono essere risolti con l'apprendimento per rinforzo avviato da dimostrazioni fornite dall'uomo."

Credito:Gupta et al.
Guppta, Hausman e i loro colleghi hanno valutato l'efficacia dell'apprendimento delle politiche di trasmissione per l'addestramento dei robot in attività a lungo orizzonte all'interno dell'ambiente di cucina simulato che hanno creato, ottenendo risultati molto promettenti. Hanno scoperto che con la giusta struttura politica e dati dimostrativi, il loro approccio ha permesso ai robot di affrontare compiti con un orizzonte molto più lungo di quanto inizialmente ritenessero possibile.
"Speriamo che le nostre scoperte possano aprire nuove strade per combinare la ricerca sull'imitazione e l'apprendimento per rinforzo e ci forniscano una potenziale direzione che possa consentire ai robot di funzionare a lungo, compiti complessi, "Hausman ha detto.
Nel futuro, l'approccio di apprendimento delle politiche a relè introdotto da Gupta, Hausman e i suoi colleghi potrebbero essere utilizzati per addestrare i robot su una gamma più ampia di compiti a lungo orizzonte. I ricercatori hanno finora testato la loro tecnica solo in un ambiente simulato; così, sarebbe interessante valutarlo in contesti reali e vedere se raggiunge risultati altrettanto promettenti.
"Come passo successivo, vorremmo approfondire il problema della generalizzazione al di là dei dati dimostrativi, " Hausman ha detto. "Alla fine, vorremmo anche migliorare ulteriormente l'efficienza dei dati del nostro metodo, passare alle osservazioni dei pixel e consentire l'apprendimento del mondo reale su un robot fisico".
© 2019 Science X Network