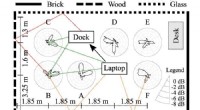
Quando giocavano al gioco di carte cooperativo Hanabi, gli umani si sentivano frustrati e confusi dalle mosse del loro compagno di squadra AI. Credito:Bryan Mastergeorge
Quando si tratta di giochi come scacchi o Go, i programmi di intelligenza artificiale (AI) hanno superato di gran lunga i migliori giocatori del mondo. Queste IA "sovrumane" sono concorrenti impareggiabili, ma forse è più difficile che competere con gli umani è collaborare con loro. La stessa tecnologia può andare d'accordo con le persone?
In un nuovo studio, i ricercatori del MIT Lincoln Laboratory hanno cercato di scoprire quanto bene gli esseri umani potessero giocare al gioco di carte cooperativo Hanabi con un modello di intelligenza artificiale avanzato addestrato per eccellere nel giocare con compagni di squadra che non avevano mai incontrato prima. In esperimenti in singolo cieco, i partecipanti hanno giocato a due serie di giochi:una con l'agente dell'IA come compagno di squadra e l'altra con un agente basato su regole, un bot programmato manualmente per giocare in un modo predefinito.
I risultati hanno sorpreso i ricercatori. Non solo i punteggi non erano migliori con il compagno di squadra AI che con l'agente basato su regole, ma gli umani odiavano costantemente giocare con il loro compagno di squadra AI. Lo hanno trovato imprevedibile, inaffidabile e inaffidabile e si sono sentiti negativamente anche quando la squadra ha segnato bene. Un documento che descrive in dettaglio questo studio è stato accettato alla Conferenza del 2021 sui sistemi di elaborazione delle informazioni neurali (NeurIPS).
"Evidenzia davvero la distinzione sfumata tra la creazione di un'IA che funziona oggettivamente bene e la creazione di un'IA soggettivamente affidabile o preferita", afferma Ross Allen, coautore del documento e ricercatore nell'Artificial Intelligence Technology Group. "Può sembrare che queste cose siano così vicine che non c'è davvero luce diurna tra di loro, ma questo studio ha dimostrato che in realtà si tratta di due problemi separati. Dobbiamo lavorare per districarli".
Gli esseri umani che odiano i loro compagni di squadra di intelligenza artificiale potrebbero essere motivo di preoccupazione per i ricercatori che progettano questa tecnologia per lavorare un giorno con gli umani su sfide reali, come difendersi dai missili o eseguire interventi chirurgici complessi. Questa dinamica, chiamata teaming intelligence, è una nuova frontiera nella ricerca sull'intelligenza artificiale e utilizza un particolare tipo di intelligenza artificiale chiamato apprendimento per rinforzo.
A un'IA di apprendimento per rinforzo non viene detto quali azioni intraprendere, ma scopre invece quali azioni producono la "ricompensa" più numerica provando gli scenari ancora e ancora. È questa tecnologia che ha prodotto i giocatori sovrumani di scacchi e go. A differenza degli algoritmi basati su regole, queste IA non sono programmate per seguire le istruzioni "se/allora", perché i possibili risultati dei compiti umani che dovrebbero affrontare, come guidare un'auto, sono troppi per essere programmati.
"L'apprendimento per rinforzo è un modo molto più generico di sviluppare l'IA. Se puoi addestrarlo per imparare a giocare a scacchi, quell'agente non guiderà necessariamente un'auto. Ma puoi usare gli stessi algoritmi per allenarti un agente diverso per guidare un'auto, dati i dati giusti", dice Allen. "Il cielo è il limite in ciò che potrebbe, in teoria, fare."
Cattivi suggerimenti, pessime giocate
Oggi i ricercatori utilizzano Hanabi per testare le prestazioni dei modelli di apprendimento per rinforzo sviluppati per la collaborazione, più o meno allo stesso modo in cui gli scacchi sono serviti da decenni come punto di riferimento per testare l'IA competitiva.
Il gioco di Hanabi è simile a una forma multiplayer di solitario. I giocatori lavorano insieme per impilare le carte dello stesso seme in ordine. Tuttavia, i giocatori non possono visualizzare le proprie carte, ma solo le carte che hanno i loro compagni di squadra. Ogni giocatore è strettamente limitato a ciò che può comunicare ai propri compagni di squadra per convincerli a scegliere la carta migliore dalla propria mano da impilare successivamente.
I ricercatori del Lincoln Laboratory non hanno sviluppato né l'IA né gli agenti basati su regole utilizzati in questo esperimento. Entrambi gli agenti rappresentano i migliori nei loro campi per le prestazioni di Hanabi. In effetti, quando il modello AI era stato precedentemente accoppiato con un compagno di squadra AI con cui non aveva mai giocato prima, la squadra ha ottenuto il punteggio più alto in assoluto per il gioco Hanabi tra due agenti AI sconosciuti.
"Questo è stato un risultato importante", dice Allen. "Abbiamo pensato, se queste IA che non si sono mai incontrate prima possono unirsi e giocare davvero bene, allora dovremmo essere in grado di portare umani che sanno anche giocare molto bene insieme all'IA, e anche loro andranno molto bene. Ecco perché pensavamo che il team di intelligenza artificiale avrebbe oggettivamente giocato meglio, e anche perché abbiamo pensato che gli umani l'avrebbero preferito, perché generalmente ci piacerà qualcosa di meglio se facciamo bene."
Nessuna di queste aspettative si è avverata. Oggettivamente, non c'era differenza statistica nei punteggi tra l'IA e l'agente basato su regole. Soggettivamente, tutti i 29 partecipanti hanno riportato nei sondaggi una chiara preferenza verso il compagno di squadra basato su regole. I partecipanti non sono stati informati con quale agente stavano giocando per quali giochi.
"Un partecipante ha affermato di essere così stressato per la cattiva azione dell'agente di intelligenza artificiale che in realtà ha avuto mal di testa", afferma Jaime Pena, ricercatore dell'AI Technology and Systems Group e autore del documento. "Un altro ha detto che pensavano che l'agente basato sulle regole fosse stupido ma praticabile, mentre l'agente dell'IA ha dimostrato di comprendere le regole, ma che le sue mosse non erano coerenti con l'aspetto di una squadra. Per loro, stava dando cattivi suggerimenti, fare brutte giocate."
Creatività disumana
Questa percezione dell'IA che fa "giochi cattivi" si collega a comportamenti sorprendenti che i ricercatori hanno osservato in precedenza nel lavoro di apprendimento per rinforzo. Ad esempio, nel 2016, quando AlphaGo di DeepMind ha sconfitto per la prima volta uno dei migliori giocatori di Go del mondo, una delle mosse più apprezzate da AlphaGo è stata la mossa 37 nel gioco 2, una mossa così insolita che i commentatori umani hanno pensato che fosse un errore. Un'analisi successiva ha rivelato che la mossa era in realtà estremamente ben calcolata ed è stata descritta come "geniale".
Tali mosse potrebbero essere elogiate quando un avversario AI le esegue, ma è meno probabile che vengano celebrate in un ambiente di squadra. I ricercatori del Lincoln Laboratory hanno scoperto che le mosse strane o apparentemente illogiche erano i peggiori trasgressori nel rompere la fiducia degli umani nel loro compagno di squadra di intelligenza artificiale in questi team strettamente accoppiati. Tali mosse non solo hanno diminuito la percezione da parte dei giocatori di quanto bene loro e il loro compagno di squadra di IA lavorassero insieme, ma anche di quanto volessero lavorare con l'IA, soprattutto quando qualsiasi potenziale vantaggio non era immediatamente evidente.
"Ci sono stati molti commenti sull'arrendersi, commenti come "Odio lavorare con questa cosa'", aggiunge Hosea Siu, anche lei autrice dell'articolo e ricercatrice nel gruppo di ingegneria dei sistemi autonomi e di controllo.
I partecipanti che si sono classificati come esperti Hanabi, cosa che ha fatto la maggior parte dei giocatori in questo studio, hanno rinunciato più spesso al giocatore AI. Siu trova questo problema preoccupante per gli sviluppatori di intelligenza artificiale, perché gli utenti chiave di questa tecnologia saranno probabilmente esperti di dominio.
"Diciamo che alleni un assistente di guida AI super intelligente per uno scenario di difesa missilistica. Non lo stai consegnando a un tirocinante; lo stai consegnando ai tuoi esperti sulle tue navi che lo fanno da 25 anni Quindi, se negli scenari di gioco c'è un forte pregiudizio da parte degli esperti, è probabile che si manifesti nelle operazioni del mondo reale", aggiunge.
Umani morbidi
I ricercatori osservano che l'IA utilizzata in questo studio non è stata sviluppata per le preferenze umane. Ma questo fa parte del problema, non molti lo sono. Come la maggior parte dei modelli di IA collaborativa, questo modello è stato progettato per ottenere il punteggio più alto possibile e il suo successo è stato valutato in base alle sue prestazioni obiettive.
Se i ricercatori non si concentrano sulla questione della preferenza umana soggettiva, "allora non creeremo un'IA che gli esseri umani vogliono effettivamente utilizzare", afferma Allen. "È più facile lavorare su un'intelligenza artificiale che migliora un numero molto pulito. È molto più difficile lavorare su un'intelligenza artificiale che funziona in questo mondo più sdolcinato di preferenze umane."
Risolvere questo problema più difficile è l'obiettivo del progetto MeRLin (Mission-Ready Reinforcement Learning), nell'ambito del quale questo esperimento è stato finanziato nell'ufficio tecnologico del Lincoln Laboratory, in collaborazione con l'acceleratore di intelligenza artificiale dell'aeronautica statunitense e il dipartimento di ingegneria elettrica e informatica del MIT Scienza. Il progetto sta studiando cosa ha impedito alla tecnologia di intelligenza artificiale collaborativa di uscire dallo spazio di gioco e di entrare in una realtà più disordinata.
I ricercatori pensano che la capacità dell'IA di spiegare le sue azioni genererà fiducia. Questo sarà il fulcro del loro lavoro per il prossimo anno.
"You can imagine we rerun the experiment, but after the fact—and this is much easier said than done—the human could ask, 'Why did you do that move, I didn't understand it?' If the AI could provide some insight into what they thought was going to happen based on their actions, then our hypothesis is that humans would say, 'Oh, weird way of thinking about it, but I get it now,' and they'd trust it. Our results would totally change, even though we didn't change the underlying decision-making of the AI," Allen says.
Like a huddle after a game, this kind of exchange is often what helps humans build camaraderie and cooperation as a team.
"Maybe it's also a staffing bias. Most AI teams don't have people who want to work on these squishy humans and their soft problems," Siu adds, laughing. "It's people who want to do math and optimization. And that's the basis, but that's not enough."
Mastering a game such as Hanabi between AI and humans could open up a universe of possibilities for teaming intelligence in the future. But until researchers can close the gap between how well an AI performs and how much a human likes it, the technology may well remain at machine versus human.