Credito:Università RUDN
I matematici dell'Università RUDN e della Libera Università di Berlino hanno proposto un nuovo approccio per studiare le distribuzioni di probabilità dei dati osservati utilizzando reti neurali artificiali. Il nuovo approccio funziona meglio con i cosiddetti outlier, cioè., oggetti di dati di input che si discostano significativamente dal campione complessivo. L'articolo è stato pubblicato sulla rivista Intelligenza artificiale .
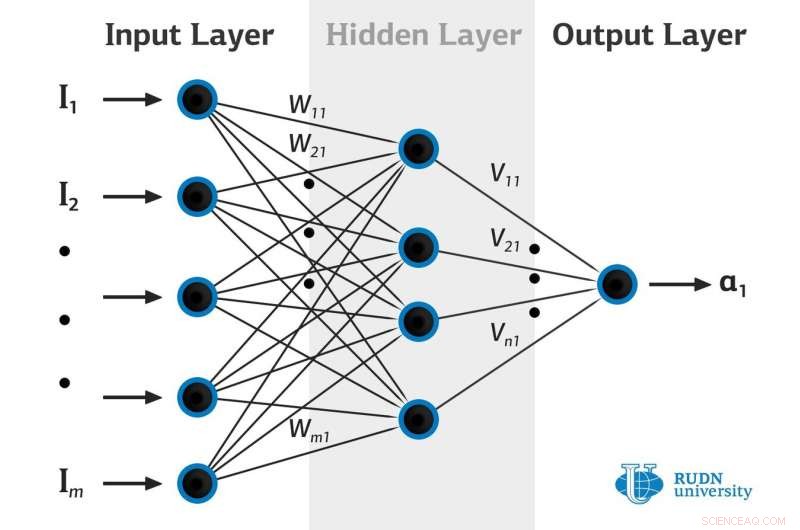
Il ripristino della distribuzione di probabilità dei dati osservati mediante reti neurali artificiali è la parte più importante dell'apprendimento automatico. La distribuzione di probabilità non solo permette di prevedere il comportamento del sistema in esame, ma anche per quantificare l'incertezza con cui si fanno le previsioni. La difficoltà principale è che, di regola, si osservano solo i dati, ma le loro esatte distribuzioni di probabilità non sono disponibili. Risolvere questo problema, Vengono utilizzati metodi approssimativi bayesiani e altri simili. Ma il loro uso aumenta la complessità di una rete neurale e quindi rende più complicato il suo addestramento.
I matematici dell'Università RUDN e della Libera Università di Berlino hanno utilizzato pesi deterministici nelle reti neurali, che aiuterebbe a superare i limiti dei metodi bayesiani. Hanno sviluppato una formula che consente di stimare correttamente la varianza della distribuzione dei dati osservati. Il modello proposto è stato testato su diversi dati:sintetici e reali; sui dati contenenti outlier e sui dati da cui sono stati rimossi gli outlier. Il nuovo metodo consente il ripristino delle distribuzioni di probabilità con una precisione precedentemente irraggiungibile.
I matematici dell'Università RUDN e della Libera Università di Berlino hanno utilizzato pesi deterministici per le reti neurali e hanno utilizzato gli output delle reti per codificare la distribuzione delle variabili latenti per la distribuzione marginale desiderata. Un'analisi delle dinamiche di addestramento di tali reti ha permesso loro di ottenere una formula che stima correttamente la varianza dei dati osservati, nonostante la presenza di outlier nei dati. Il modello proposto è stato testato su dati diversi:sintetici e reali. Il nuovo metodo consente di ripristinare le distribuzioni di probabilità con maggiore precisione rispetto ad altri metodi moderni. L'accuratezza è stata valutata utilizzando il metodo AUC (l'area sotto la curva è l'area sotto il grafico che consente di valutare l'errore quadratico medio delle previsioni in funzione della dimensione del campione stimata dalla rete come "affidabile"; maggiore è il punteggio AUC, migliori sono le previsioni).