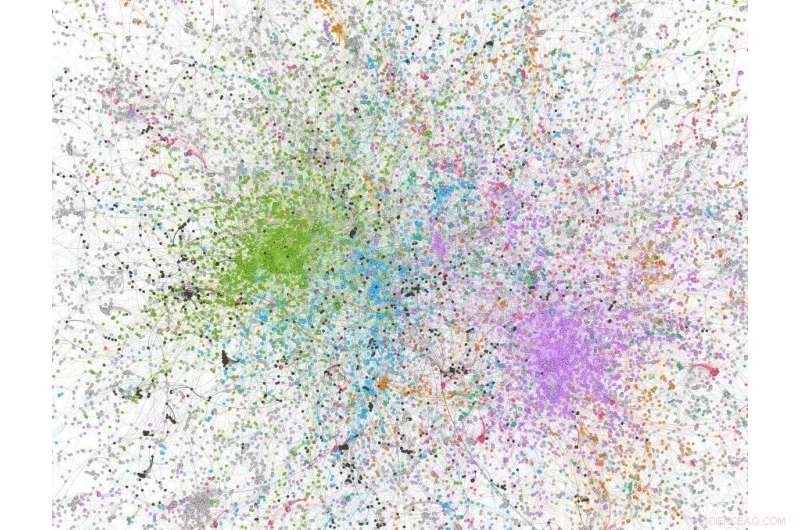
Cifra dell'analisi di rete derivata da un campione di 100, 000 tweet con 'covid' nel tweet; i nodi colorati in verde sono utenti/organizzazioni di Twitter alt-right/fortemente conservatori. Credito:Dhiraj Murthy, UT Austin
Della miriade di modi in cui i ricercatori stanno combattendo la diffusione del coronavirus, studiare i Tweet potrebbe non essere il primo che mi viene in mente. Ma ora, come nelle crisi passate, attingere a uno dei principali servizi di messaggistica in tempo reale al mondo può aiutare a identificare nuovi hotspot pandemici, evidenziare nuovi sintomi, o interpretare il modo in cui le persone e le comunità stanno rispondendo agli ordini di praticare il distanziamento sociale.
Il team di esperti di data science del Texas Advanced Computing Center (TACC) ha facilitato l'analisi dei social media in passato, e ha sviluppato strumenti di apprendimento automatico per estrarre meglio gli aghi di conoscenza dai vasti mucchi di fieno del Twitterverse.
A partire da marzo, TACC ha iniziato a ingerire grandi quantità di tweet ogni giorno:circa 40 milioni di messaggi, di cui un milione sono unici. Combinando la loro collezione con sforzi simili dei gruppi di UT Austin, l'Università della California del Sud, e la George State University, hanno esteso la loro raccolta di tweet relativi a COVID-19 fino a gennaio. (La settimana scorsa, Twitter ha annunciato che rilascerà nuovi endpoint API per la propria raccolta di tweet relativi a COVID-19 per sviluppatori e ricercatori approvati.)
"C'è un grande interesse per questi tipi di raccolte. È molto utile nella scienza dei dati, " disse Weijia Xu, che gestisce il gruppo Scalable Computational Intelligence presso TACC.
Oggi, TACC ha annunciato un nuovo repository GitHub in cui i ricercatori interessati possono accedere sia ai puntatori ai dati grezzi di Twitter relativi a COVID-19 sia alle analisi su larga scala facilitate dai supercomputer di TACC.
La prima delle analisi a disposizione dei ricercatori è un insieme di n-grammi:sequenze contigue di parole da un dato campione di tweet. Il primo 1, 000 uno-, Due-, e sequenze di tre parole sono state assemblate per ogni giorno della pandemia. L'assemblaggio anche di un singolo grammo da diversi milioni di tweet potrebbe richiedere fino a un'ora su un laptop a causa della quantità di elaborazione dei dati coinvolti, ma può essere fatto in pochi minuti sui supercomputer di TACC.
Il gruppo di ricerca TACC, guidato da Xu, ha anche lavorato su analisi di modelli tematici, identificare i termini che appaiono frequentemente in connessione tra loro, anche se non necessariamente in ordine. Questi verranno aggiunti al repository GitHub nelle prossime settimane.
Entrambi i metodi di raggruppamento possono essere utili per identificare le tendenze nel modo in cui la pandemia, e la risposta della gente ad esso, stanno evolvendo.
I progetti futuri che utilizzano i dati includono un database pubblico ricercabile; analisi delle entità:ispezione di tweet per entità note come personaggi pubblici o organizzazioni e restituzione di informazioni su tali entità; e rilevamento degli eventi:rilevamento automatico del verificarsi di eventi e loro classificazione.
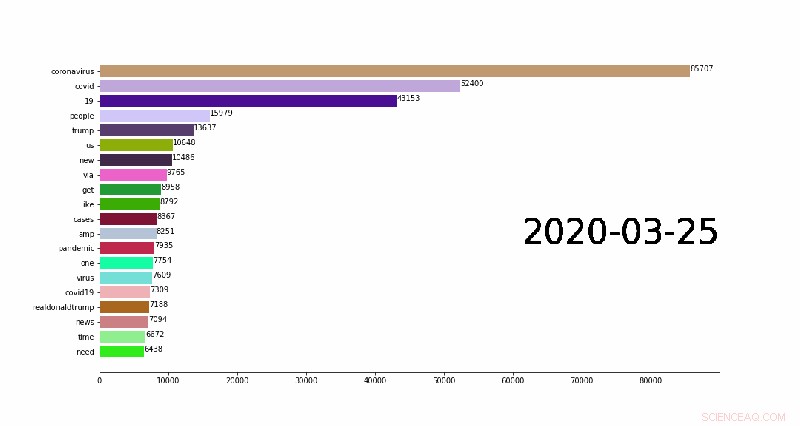
Un'animazione che mostra i primi 20 n-grammi giornalieri (parole comuni nei post di Twitter) che cambiano nel tempo. Credito:Weijia Xu, TACC
Questi sforzi saranno facilitati da strumenti sviluppati presso TACC, come il progetto Domain Information &Vocabulary Extraction, uno sforzo finanziato dalla National Science Foundation per estrarre entità biologiche da pubblicazioni e altri documenti di testo utilizzando l'apprendimento automatico, che è stato adattato per altri tipi di estrazione.
L'obiettivo principale di TACC:qui, come nella maggior parte delle cose, è facilitare la ricerca degli altri e le scoperte di potere. "Siamo principalmente interessati a consentire alle persone di accedere a set di dati curati e ad aiutarli a fare ricerche, " ha detto Xu. "Stiamo raccogliendo, pulire, ed elaborare i dati in modo che siano pronti per l'uso da parte di altri."
I ricercatori dell'Università del Texas ad Austin (UT Austin) sono tra i primi a esprimere interesse per l'utilizzo dei set di dati Twitter di TACC COVID-19 per ricerche mirate.
"The TACC COVID-19 Twitter collection will be invaluable in enabling us to model communication patterns and topics that emerge across stages of the disease, " said Sharon Stover, a professor in the Moody College of Communications. "We may be able to compare the timeline to similar data from other countries such as China that experienced the epidemic earlier. This may lead us toward understanding when typical responses occur and help us to characterize how populations make sense of health pandemics at certain stages in an epidemic's process."
Strover is particularly interested in learning how one might segment tweets by certain population features to learn more about sub-networks that pass along certain information—or ignore it.
Dhiraj Murthy, an associate professor of Journalism and Sociology at UT Austin and author of the first scholarly book about Twitter, plans to use the dataset for his academic work.
"My lab is in the very initial stages of using these data to study two research questions:To what extent is fake news, misinformation, and disinformation regarding COVID-19 present on social media platforms? And:Are social media platforms being used as venues for racist messaging against people of Chinese/Asian origin within COVID-19-related posts?"
Matt Lease, from the UT School of Information, has been using the database to research misinformation in collaboration with Murthy, and also to identify incidents of racist messaging. "The large dataset TACC is collecting, along with its computing and storage services, plus excellent researchers and staff, makes it a fantastic resource for researchers interested in studying and combatting the spread of racist messaging on Twitter."
Both in the moment, and for retrospective analyses, Twitter data can be an incredible resource.
Said TACC research associate Ruizhu Huang:"The large volume of tweets collected at TACC provides a valuable date source to explore various perspectives on COVID-19. And the storage and supercomputing power at TACC will tremendously speed up the data analysis process."