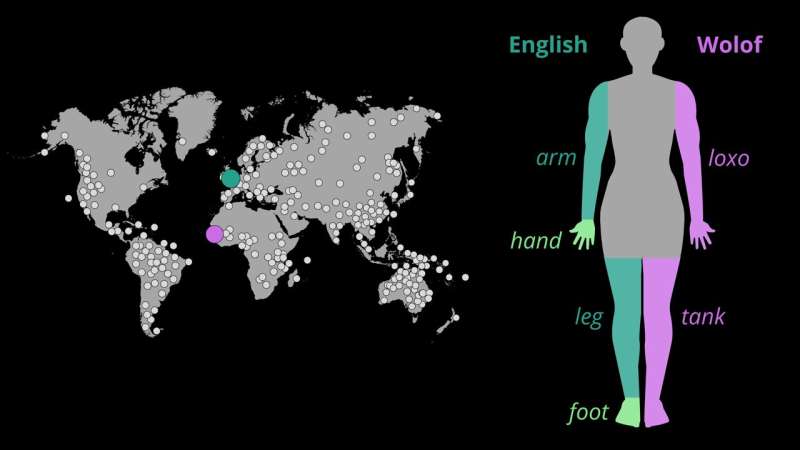
I corpi umani hanno disegni simili. Tuttavia, le lingue differiscono nel modo in cui dividono il corpo in parti e danno loro un nome. Ad esempio, gli anglofoni hanno due parole per piede e gamba, mentre altre lingue esprimono i concetti piede e gamba in una sola parola.
Lo studio della variazione dei vocabolari delle parti del corpo nelle diverse lingue ha attirato per molti anni l'attenzione dei ricercatori in linguistica, antropologia e psicologia. Analogamente ai principi sviluppati per il dominio semantico del colore, le tendenze universali sono state identificate e messe a confronto con variazioni specifiche della cultura.
L'emergere di nuovi metodi nell'analisi di rete ha reso possibile condurre confronti su larga scala del vocabolario in domini semantici specifici per studiare strutture universali e culturali.
Il professor Johann-Mattis List, che dirige la cattedra di Linguistica computazionale multilingue presso l'Università di Passau, è uno dei ricercatori che hanno sviluppato algoritmi per far luce sulla questione di come gli esseri umani formano il loro vocabolario in diverse lingue.
Si è unito ai ricercatori del Dipartimento di evoluzione linguistica e culturale dell'Istituto Max Planck di antropologia evolutiva di Lipsia, nel loro studio che confrontava il vocabolario delle parti del corpo in 1.028 lingue.
Lo studio, intitolato "I fattori universali e culturali modellano i vocabolari delle parti del corpo", è stato ora pubblicato su Scientific Reports .
"Sebbene i nostri corpi seguano schemi simili, le lingue differiscono nel modo in cui dividono il corpo in parti e danno loro un nome", afferma Annika Tjuka, ex studentessa di dottorato presso il Professor List e ora ricercatrice post-dottorato presso MPI-EVA, che ha avviato e condotto lo studio.
"In inglese, abbiamo una parola per braccio e un'altra per mano, ma il wolof, una lingua parlata in Senegal nell'Africa occidentale, usa una parola, loxo, per riferirsi a entrambe le parti del corpo. Chi parla entrambe le lingue ha un corpo umano. Quindi perché differiscono in quanto alle parti vengono assegnati nomi univoci?"
I risultati confermano il principio secondo cui se esiste una parola separata per piede, ce ne sarà anche una per mano. Ma i risultati mostrano anche che è più probabile che una parte del corpo adiacente ad un’altra abbia lo stesso nome. Uno dei motivi di questo modello è che lingue come il wolof si concentrano ed enfatizzano le caratteristiche funzionali che collegano due parti.
I parlanti riconoscono che lanciamo una palla con la mano e il braccio o che camminiamo con la gamba e il piede. Lingue come l'inglese, invece, si concentrano su segnali visivi come il polso o la caviglia per separare le parti.
I vocabolari delle parti del corpo variano da lingua a lingua. Tuttavia, all’interno di questa diversità emergono tendenze generali. "Per comprendere i fattori che modellano la diversità linguistica, abbiamo bisogno di più dati. Dobbiamo documentare le lingue parlate in aree linguisticamente diverse. E dobbiamo raccogliere dati sul contesto sociologico in cui le lingue sono parlate", afferma il dott. Tjuka.
Per lo studio attuale, il team di linguisti ha utilizzato una banca dati esistente, Lexibank, sviluppata dai ricercatori dell’MPI-EVA di Lipsia e della Cattedra di Linguistica Computazionale Multilingue di Passau. Si tratta di una vasta raccolta di elenchi di parole nelle lingue del mondo.
Con un approccio computazionale, i ricercatori di Passau e Lipsia hanno estratto le parole per 36 parti del corpo in tutte queste lingue e hanno analizzato le relazioni tra le parole in un'analisi di rete.
"Ci sono voluti diversi anni per mettere insieme i dati nella raccolta Lexibank", dice il professor List, che ha lavorato come ricercatore senior presso l'MPI-EVA di Lipsia. "Ora possiamo iniziare ad analizzare i dati in vari modi."
Il professor List dirige il gruppo di ricerca "ProduSemy" dell'Università di Passau. Insieme al suo gruppo di ricerca utilizza anche il database per capire come si formano le famiglie di parole nelle lingue.
Ulteriori informazioni: Annika Tjuka et al, Fattori universali e culturali modellano i vocabolari delle parti del corpo, Rapporti scientifici (2024). DOI:10.1038/s41598-024-61140-0
Informazioni sul giornale: Rapporti scientifici
Fornito dall'Universität Passau