Credito:Gerlach et al.
Ricercatori della Northwestern University, l'Università di Bath, e l'Università di Sydney hanno sviluppato un nuovo approccio di rete ai modelli tematici, strategie di apprendimento automatico in grado di scoprire argomenti astratti e strutture semantiche all'interno di documenti di testo.
"Una delle principali sfide computazionali e scientifiche nell'era moderna è estrarre informazioni utili da testi non strutturati, " I ricercatori hanno spiegato nel loro studio. "I modelli di argomento sono un popolare approccio di apprendimento automatico che deduce la struttura topica latente di una raccolta di documenti".
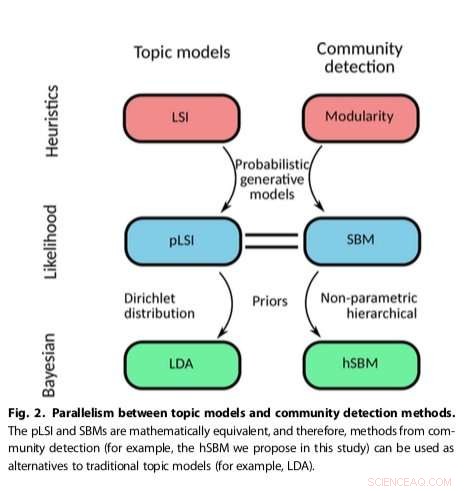
I modelli di argomento sono attualmente utilizzati per identificare testi correlati semanticamente e classificare i documenti all'interno di una serie di campi, compresa la sociologia, storia, linguistica, e psicologia. Il metodo più comunemente usato, allocazione di Dirichlet latente (LDA), è utilizzato anche per bibliometria, analisi psicologica e politica, così come per l'elaborazione delle immagini.
Nonostante il suo diffuso successo, LDA presenta diversi difetti nel modo in cui rappresenta il testo, come la mancanza di metodo per scegliere il numero di argomenti, discrepanze con le proprietà statistiche dei testi reali e una mancanza di giustificazione per il priore bayesiano, che nell'inferenza statistica bayesiana è la distribuzione di probabilità espressa prima che l'evidenza sia presentata.
Credito:Gerlach et al.
Gran parte della ricerca recente sui modelli tematici si è concentrata sulla creazione di versioni più sofisticate di LDA che offrono prestazioni migliori o possono analizzare efficacemente aspetti particolari dei documenti.
L'approccio sviluppato da questo team di ricercatori deriva dalla teoria delle reti, una teoria utilizzata in fisica e in altri campi scientifici che fornisce tecniche per l'analisi dei grafici, così come strutture in sistemi con diversi agenti interagenti. Il loro nuovo framework per la modellazione di argomenti si basa sull'approccio utilizzato per trovare comunità in reti complesse, quale, nel contesto della teoria delle reti, è un grafico con caratteristiche che si verificano nella modellazione di sistemi reali.
"Stavo lavorando sul linguaggio naturale e sulla modellazione di argomenti dal punto di vista di sistemi complessi e reti complesse, "Martin Gerlach, borsista postdottorato presso la Northwestern University ha detto TechXplore. "I problemi sembravano molto simili, tuttavia le comunità dell'informatica (modellazione di argomenti) e delle reti complesse sembravano funzionare in gran parte in modo indipendente. Essere formato come fisico, volevamo dimostrare che due problemi apparentemente diversi potevano essere ridotti alla stessa matematica di base".
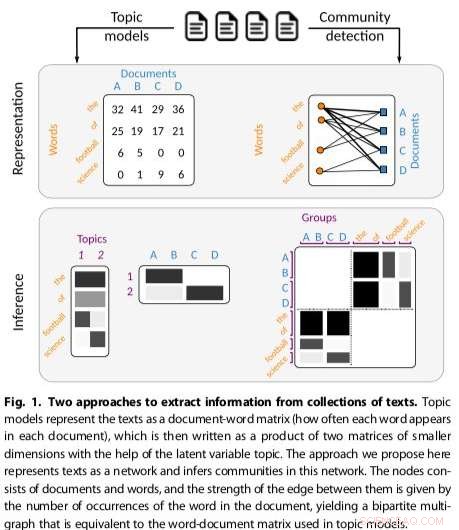
Gerlach ei suoi colleghi hanno ideato un nuovo approccio per identificare le strutture topiche che si riferiscono al problema di trovare comunità in reti complesse. La loro tecnica rappresenta i corpora testuali come reti bipartite, una classe di reti complesse che dividono i nodi in insiemi X e Y, consentendo solo connessioni tra nodi in insiemi diversi.
Credito:Gerlach et al.
"Abbiamo mappato il problema del topic modeling al problema del rilevamento della comunità in una rete composta da parole e documenti che dimostrano che sono matematicamente equivalenti, " ha spiegato Gerlach.
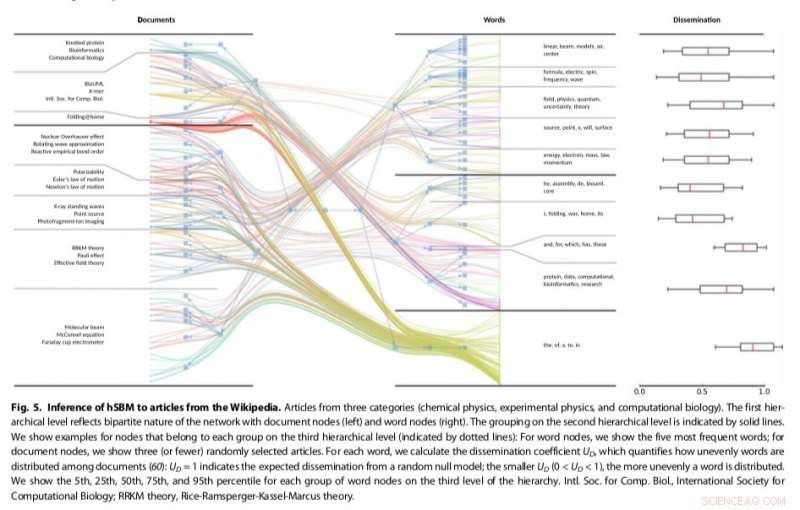
L'approccio dei ricercatori che adatta i metodi di rilevamento della comunità esistenti, è risultato essere più versatile e basato sui principi rispetto ad altri modelli tematici esistenti, ad esempio rilevare il numero di argomenti presenti nei testi e raggruppare gerarchicamente sia le parole che i documenti. Il loro metodo utilizzava un modello a blocchi stocastici (SBM), un modello generativo per grafici che mappa generalmente le comunità, sottoinsiemi di elementi che sono collegati tra loro.
"Risolviamo alcuni dei problemi intrinseci e noti dei popolari algoritmi di modellazione di argomenti come LDA (ad esempio come determinare il numero di argomenti), " disse Gerlach. "Inoltre, il nostro lavoro mostra come mettere in relazione formalmente i metodi di rilevamento della comunità e modellazione di argomenti, aprendo la possibilità di fertilizzazione incrociata tra questi due campi."
L'approccio SBM sviluppato da Gerlach e dai suoi colleghi potrebbe avere interessanti applicazioni in altre aree in cui viene utilizzato l'apprendimento automatico, come l'analisi di codici genetici o immagini. In futuro, i ricercatori intendono continuare a esplorare il potenziale delle reti complesse sia nel contesto dell'analisi del testo che oltre.
"L'equivalenza tra la modellazione degli argomenti e il rilevamento della comunità consente di utilizzare le conoscenze acquisite in ciascuna delle comunità e applicarle all'altro dominio, " ha detto Gerlach. "Spero di utilizzare queste intuizioni per ottenere una migliore comprensione di questi algoritmi di apprendimento automatico; perché funzionano, e, cosa più importante, a quali condizioni non funzionano".
© 2018 Tech Xplore