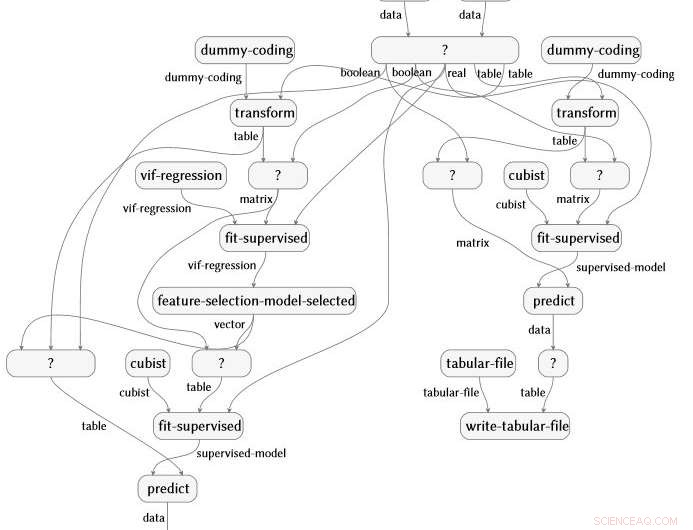
Rappresentazione del grafico di flusso semantico prodotta automaticamente da un'analisi dei dati sull'artrite reumatoide. Credito:IBM
Abbiamo assistito a significativi progressi recenti nell'analisi dei modelli e nell'intelligenza artificiale applicata alle immagini, segnali audio e video, e testo in linguaggio naturale, ma non altrettanto applicato a un altro artefatto prodotto dalle persone:il codice sorgente del programma per computer. In un paper da presentare al FEED Workshop a KDD 2018, mostriamo un sistema che fa progressi verso l'analisi semantica del codice. Facendo così, forniamo le basi per le macchine per ragionare veramente sul codice del programma e imparare da esso.
Il lavoro, anche recentemente dimostrato all'IJCAI 2018, è concepito e guidato da Evan Patterson, collega di IBM Science for Social Good, e si concentra specificamente sul software di data science. I programmi di data science sono un tipo speciale di codice informatico, spesso abbastanza breve, ma pieno di contenuti semanticamente ricchi che specificano una sequenza di trasformazione dei dati, analisi, modellazione, e operazioni di interpretazione. La nostra tecnica esegue un'analisi dei dati (immagina uno script R o Python) e acquisisce tutte le funzioni chiamate nell'analisi. Quindi collega queste funzioni a un'ontologia di data science che abbiamo creato, esegue diversi passaggi di semplificazione, e produce una rappresentazione grafica del flusso semantico del programma. Come esempio, il grafico di flusso sottostante è prodotto automaticamente da un'analisi dei dati sull'artrite reumatoide.
La tecnica è applicabile attraverso scelte di linguaggio di programmazione e pacchetto. I tre frammenti di codice seguenti sono scritti in R, Python con i pacchetti NumPy e SciPy, e Python con i pacchetti Pandas e Scikit-learn. Tutti producono esattamente lo stesso grafo di flusso semantico.
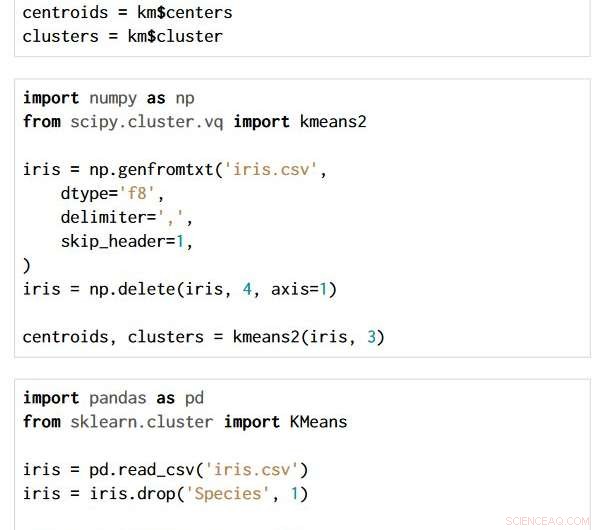
Credito:IBM
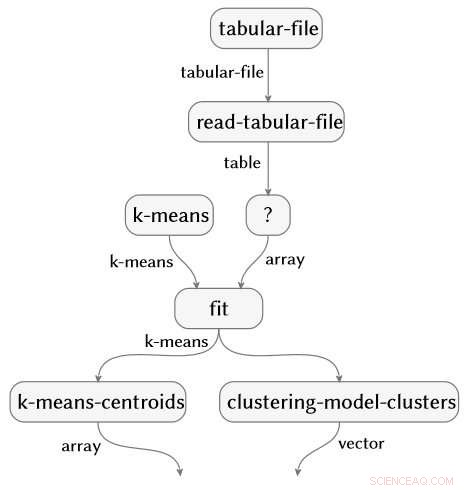
Credito:IBM
Possiamo pensare al grafo di flusso semantico che estraiamo come un singolo punto dati, proprio come un'immagine o un paragrafo di testo, su cui svolgere ulteriori compiti di livello superiore. Con la rappresentazione che abbiamo sviluppato, possiamo abilitare diverse funzionalità utili per la pratica dei data scientist, compresa la ricerca intelligente e il completamento automatico delle analisi, raccomandazione di analisi simili o complementari, visualizzazione dello spazio di tutte le analisi condotte su un particolare problema o dataset, traduzione o trasferimento di stile, e persino la generazione automatica di nuove analisi dei dati (cioè la creatività computazionale), il tutto basato sulla comprensione veramente semantica di ciò che fa il codice.
La Data Science Ontology è scritta in un nuovo linguaggio ontologico che abbiamo sviluppato chiamato Monoidal Ontology and Computing Language (Monocl). Questa linea di lavoro è stata avviata nel 2016 in collaborazione con il progetto di cura accelerata per la sclerosi multipla.
Questa storia è stata ripubblicata per gentile concessione di IBM Research. Leggi la storia originale qui.