Credito:CC0 Dominio Pubblico
I medici delle unità di terapia intensiva devono affrontare un dilemma continuo:ogni esame del sangue che ordinano potrebbe fornire informazioni critiche, ma aggiunge anche costi e rischi per i pazienti. Per affrontare questa sfida, i ricercatori della Princeton University stanno sviluppando un approccio computazionale per aiutare i medici a monitorare in modo più efficace le condizioni dei pazienti e prendere decisioni sulle migliori opportunità per ordinare test di laboratorio per pazienti specifici.
Utilizzando i dati di più di 6, 000 pazienti, gli studenti laureati Li-Fang Cheng e Niranjani Prasad hanno lavorato con la professoressa associata di informatica Barbara Engelhardt per progettare un sistema che potesse ridurre la frequenza dei test e migliorare i tempi dei trattamenti critici. Il team ha presentato i risultati il 6 gennaio al Pacific Symposium on Biocomputing alle Hawaii.
L'analisi si è concentrata su quattro esami del sangue che misuravano il lattato, creatinina, azoto ureico nel sangue e globuli bianchi. Questi indicatori vengono utilizzati per diagnosticare due problemi pericolosi per i pazienti in terapia intensiva:insufficienza renale o un'infezione sistemica chiamata sepsi.
"Poiché uno dei nostri obiettivi era pensare alla possibilità di ridurre il numero di test di laboratorio, abbiamo iniziato a guardare i pannelli [analisi del sangue] che sono più ordinati, " disse Cheng, co-autore principale dello studio insieme a Prasad.
I ricercatori hanno lavorato con il database MIMIC III, che include registrazioni dettagliate di 58, 000 ricoveri in terapia intensiva presso il Beth Israel Deaconess Medical Center di Boston. Per lo studio, i ricercatori hanno selezionato un sottoinsieme di 6, 060 registrazioni di adulti che sono rimasti in terapia intensiva da uno a 20 giorni e hanno avuto misurazioni per segni vitali comuni e test di laboratorio.
"Questi dati medici, alla scala di cui stiamo parlando, fondamentalmente sono diventati disponibili nell'ultimo anno o due in modo da poterli analizzare con metodi di apprendimento automatico, " disse Engelhardt, l'autore senior dello studio. "È super eccitante, e una grande opportunità".
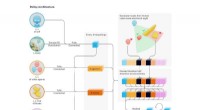
L'algoritmo del team utilizza una "funzione di ricompensa" che incoraggia un ordine di test basato su quanto informativo è il test in un dato momento. Questo è, c'è una maggiore ricompensa nella somministrazione di un test se c'è una maggiore probabilità che lo stato di un paziente sia significativamente diverso dall'ultima misurazione, e se è probabile che il risultato del test suggerisca un intervento clinico come l'inizio di antibiotici o l'assistenza alla respirazione attraverso la ventilazione meccanica. Allo stesso tempo, la funzione aggiunge una penalità per il costo monetario del test e il rischio per il paziente. Prasad ha osservato che, dipende dalla situazione, un medico potrebbe decidere di dare la priorità a uno di questi componenti rispetto ad altri.
Questo approccio, noto come apprendimento per rinforzo, mira a raccomandare decisioni che massimizzino la funzione di ricompensa. Questo tratta la questione dei test medici "come il problema del processo decisionale sequenziale che è, dove tieni conto di tutte le decisioni e di tutti gli stati che hai visto nel periodo di tempo passato e decidi cosa dovresti fare in un momento attuale per massimizzare i premi a lungo termine per il paziente, "ha spiegato Prasad, uno studente laureato in informatica.
L'ordinamento di queste informazioni in modo tempestivo per un ambiente clinico richiede una notevole potenza di calcolo, disse Engelhardt, un membro di facoltà associato del Princeton Institute for Computational Science and Engineering (PICSciE). Cheng, uno studente laureato in ingegneria elettrica, ha lavorato con il suo co-consigliere Kai Li, il professore di informatica Paul M. e Marcia R. Wythes, per eseguire i calcoli del team utilizzando le risorse PICSciE.
Per testare l'utilità della politica di test di laboratorio che hanno sviluppato, i ricercatori hanno confrontato i valori della funzione di ricompensa che sarebbero risultati dall'applicazione della loro politica ai regimi di test effettivamente utilizzati per il 6, 060 pazienti nel set di dati di allenamento, che sono stati ricoverati in terapia intensiva tra il 2001 e il 2012. Hanno anche confrontato questi valori con quelli che sarebbero risultati dalle politiche di test di laboratorio randomizzati.
Per ogni componente di prova e ricompensa, la politica generata dall'algoritmo di apprendimento automatico avrebbe portato a valori di ricompensa migliori rispetto alle politiche effettive utilizzate in ospedale. Nella maggior parte dei casi, l'algoritmo ha anche superato le politiche casuali. Il test del lattato è stata un'eccezione notevole; questo potrebbe essere spiegato dalla frequenza relativamente bassa degli ordini di test del lattato, portando ad un alto grado di varianza nell'informatività del test.
Globale, l'analisi dei ricercatori ha mostrato che la loro politica ottimizzata avrebbe prodotto più informazioni rispetto al regime di test effettivo seguito dai medici. L'utilizzo dell'algoritmo avrebbe potuto ridurre il numero di ordini di test di laboratorio fino al 44 percento nel caso dei test dei globuli bianchi. Hanno anche dimostrato che questo approccio avrebbe aiutato a informare i medici di intervenire a volte ore prima quando le condizioni di un paziente hanno cominciato a peggiorare.
"Con la politica di ordinazione dei test di laboratorio sviluppata da questo metodo, siamo stati in grado di ordinare ai laboratori di determinare che la salute del paziente era abbastanza degradata da aver bisogno di cure, in media, quattro ore prima che il medico iniziasse effettivamente il trattamento sulla base dei laboratori ordinati dal medico, " disse Engelhardt.
"C'è una scarsità di linee guida basate sull'evidenza in terapia intensiva per quanto riguarda la frequenza appropriata delle misurazioni di laboratorio, " disse Shamim Nemati, un assistente professore di informatica biomedica presso la Emory University che non è stato coinvolto nello studio. "Approcci basati sui dati come quello proposto da Cheng e co-autori, quando combinato con una visione più approfondita del flusso di lavoro clinico, hanno il potenziale per ridurre l'onere della creazione di grafici e il costo di test eccessivi, e migliorare la consapevolezza della situazione e i risultati."
Il gruppo di Engelhardt sta collaborando con i data scientist del Predictive Healthcare Team di Penn Medicine per introdurre questa politica nella clinica entro i prossimi anni. Tali sforzi mirano a "dare ai medici i superpoteri che vengono dati ad altre persone in altri domini, ", ha affermato Corey Chivers, Senior Data Scientist di Penn. "Avere accesso all'apprendimento automatico, intelligenza artificiale e modelli statistici con grandi quantità di dati" aiuteranno i medici a "prendere decisioni migliori, e, infine, migliorare i risultati per i pazienti, " Ha aggiunto.
"Questa è una delle prime volte che saremo in grado di adottare questo approccio di apprendimento automatico e metterlo effettivamente in terapia intensiva, o in un ambiente ospedaliero ospedaliero, e consigliare gli operatori sanitari in modo che i pazienti non siano a rischio, " ha detto Engelhardt. "Questo è davvero qualcosa di nuovo."
Questo lavoro è stato sostenuto dall'Helen Shipley Hunt Fund, che sostiene la ricerca volta a migliorare la salute umana; e il Fondo Eric e Wendy Schmidt per l'innovazione strategica, che supporta la ricerca nell'intelligenza artificiale e nell'apprendimento automatico.