Molti studi scientifici non resistono in ulteriori test. Credito:fotografia A e N/Shutterstock.com
In una sperimentazione di un nuovo farmaco per curare il cancro, Il 44% di 50 pazienti ha raggiunto la remissione dopo il trattamento. Senza il farmaco, solo il 32% dei pazienti precedenti ha fatto lo stesso. Il nuovo trattamento sembra promettente, ma è migliore dello standard?
Questa domanda è difficile, quindi gli statistici tendono a rispondere a una domanda diversa. Guardano i loro risultati e calcolano qualcosa chiamato valore p. Se il valore p è inferiore a 0,05, i risultati sono "statisticamente significativi" – in altre parole, improbabile che sia causato da un caso casuale.
Il problema è, molti risultati statisticamente significativi non si replicano. Un trattamento che mostra la promessa in uno studio non mostra alcun beneficio quando viene somministrato al successivo gruppo di pazienti. Questo problema è diventato così grave che una rivista di psicologia ha addirittura bandito del tutto i valori p.
I miei colleghi ed io abbiamo studiato questo problema, e pensiamo di sapere cosa lo sta causando. La barra per rivendicare la significatività statistica è semplicemente troppo bassa.
La maggior parte delle ipotesi sono false
La collaborazione scientifica aperta, un'organizzazione senza scopo di lucro focalizzata sulla ricerca scientifica, cercato di replicare 100 esperimenti di psicologia pubblicati. Mentre 97 degli esperimenti iniziali riportavano risultati statisticamente significativi, solo 36 degli studi replicati lo hanno fatto.
Diversi studenti laureati e io abbiamo usato questi dati per stimare la probabilità che un esperimento di psicologia scelto a caso verificasse un effetto reale. Abbiamo scoperto che solo il 7% circa lo ha fatto. In uno studio simile, l'economista Anna Dreber e colleghi hanno stimato che solo il 9% degli esperimenti si sarebbe replicato.
Entrambe le analisi suggeriscono che solo circa uno su 13 nuovi trattamenti sperimentali in psicologia – e probabilmente molte altre scienze sociali – si rivelerà un successo.
Ciò ha importanti implicazioni quando si interpretano i valori p, in particolare quando sono vicini a 0,05.
Il fattore Bayes
È più probabile che valori di P vicini a 0,05 siano dovuti a casualità di quanto la maggior parte delle persone creda.
Per capire il problema, torniamo al nostro immaginario studio sui farmaci. Ricordare, 22 pazienti su 50 trattati con il nuovo farmaco sono andati in remissione, rispetto a una media di appena 16 pazienti su 50 con il vecchio trattamento.
La probabilità di vedere 22 o più successi su 50 è 0,05 se il nuovo farmaco non è migliore del vecchio. Ciò significa che il p-value per questo esperimento è statisticamente significativo. Ma vogliamo sapere se il nuovo trattamento è davvero un miglioramento, o se non è migliore del vecchio modo di fare le cose.
Per scoprirlo, dobbiamo combinare le informazioni contenute nei dati con le informazioni disponibili prima che l'esperimento fosse condotto, o le "quote precedenti". Le quote precedenti riflettono fattori che non sono misurati direttamente nello studio. Ad esempio, potrebbero spiegare il fatto che in altri 10 studi su farmaci simili, nessuno si è rivelato vincente.
Se il nuovo farmaco non è migliore del vecchio farmaco, poi le statistiche ci dicono che la probabilità di vedere esattamente 22 su 50 successi in questo studio è 0,0235 – relativamente bassa.
E se il nuovo farmaco fosse effettivamente migliore? In realtà non conosciamo il tasso di successo del nuovo farmaco, ma una buona ipotesi è che sia vicino al tasso di successo osservato, 22 su 50. Se assumiamo che, quindi la probabilità di osservare esattamente 22 successi su 50 è 0,113, circa cinque volte più probabile. (Non quasi 20 volte più probabile, anche se, come puoi immaginare se sapessi che il valore p dell'esperimento era 0,05.)
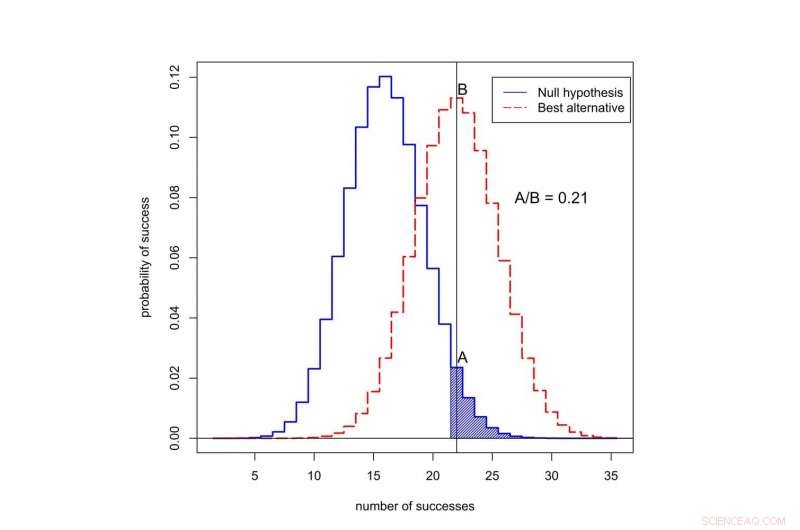
Qual è la probabilità di osservare il successo in 50 prove? La curva nera rappresenta le probabilità sotto l'"ipotesi nulla, ' quando il nuovo trattamento non è migliore del vecchio. La curva rossa rappresenta le probabilità quando il nuovo trattamento è migliore. L'area ombreggiata rappresenta il p-value. In questo caso, il rapporto delle probabilità assegnate a 22 successi è A diviso B, o 0,21. Credito:Valen Johnson, CC BY-SA
Questo rapporto delle probabilità è chiamato fattore di Bayes. Possiamo usare il teorema di Bayes per combinare il fattore di Bayes con le probabilità precedenti per calcolare la probabilità che il nuovo trattamento sia migliore.
Per amor di discussione, supponiamo che solo 1 su 13 trattamenti sperimentali contro il cancro si rivelerà un successo. È vicino al valore che abbiamo stimato per gli esperimenti di psicologia.
Quando combiniamo queste quote precedenti con il fattore Bayes, si scopre che la probabilità che il nuovo trattamento non sia migliore del vecchio è almeno 0,71. Ma il p-value statisticamente significativo di 0,05 suggerisce esattamente il contrario!
Un nuovo approccio
Questa incoerenza è tipica di molti studi scientifici. È particolarmente comune per valori di p intorno a 0,05. Questo spiega perché una percentuale così alta di risultati statisticamente significativi non si replica.
Quindi, come dovremmo valutare le affermazioni iniziali di una scoperta scientifica? Nel mese di settembre, io e i miei colleghi abbiamo proposto una nuova idea:solo i valori di P inferiori a 0,005 dovrebbero essere considerati statisticamente significativi. I valori di p tra 0,005 e 0,05 dovrebbero essere semplicemente definiti suggestivi.
Nella nostra proposta, risultati statisticamente significativi hanno maggiori probabilità di replicarsi, anche dopo aver tenuto conto delle piccole probabilità precedenti che in genere riguardano gli studi nel sociale, scienze biologiche e mediche.
Cosa c'è di più, pensiamo che la significatività statistica non dovrebbe fungere da soglia luminosa per la pubblicazione. Potrebbero essere pubblicati anche risultati statisticamente indicativi, o addirittura risultati in gran parte inconcludenti, in base al fatto che riportassero o meno importanti prove preliminari sulla possibilità che una nuova teoria potesse essere vera.
L'11 ottobre abbiamo presentato questa idea a un gruppo di statistici all'ASA Symposium on Statistical Inference a Bethesda, Maryland. Il nostro obiettivo nel cambiare la definizione di significatività statistica è ripristinare il significato previsto di questo termine:quei dati hanno fornito un supporto sostanziale per una scoperta scientifica o un effetto terapeutico.
Critiche alla nostra idea
Non tutti sono d'accordo con la nostra proposta, compreso un altro gruppo di scienziati guidati dallo psicologo Daniel Lakens.
Sostengono che la definizione dei fattori di Bayes è troppo soggettiva, e che i ricercatori possono fare altre ipotesi che potrebbero cambiare le loro conclusioni. Nella sperimentazione clinica, Per esempio, Lakens potrebbe sostenere che i ricercatori potrebbero riportare il tasso di remissione di tre mesi anziché di sei mesi, se fornisse prove più forti a favore del nuovo farmaco.
Lakens e il suo gruppo ritengono inoltre che la stima secondo cui solo un esperimento su 13 si replicherà è troppo bassa. Sottolineano che questa stima non include effetti come p-hacking, un termine per quando i ricercatori analizzano ripetutamente i loro dati finché non trovano un forte p-value.
Invece di alzare l'asticella della significatività statistica, il gruppo Lakens pensa che i ricercatori dovrebbero stabilire e giustificare il proprio livello di significatività statistica prima di condurre i loro esperimenti.
Non sono d'accordo con molte delle affermazioni del gruppo Lakens – e, da un punto di vista puramente pratico, Sento che la loro proposta è un non-starter. La maggior parte delle riviste scientifiche non fornisce ai ricercatori un meccanismo per registrare e giustificare la scelta dei valori p prima di condurre esperimenti. Ma ancora più importante, consentire ai ricercatori di stabilire le proprie soglie di evidenza non sembra un buon modo per migliorare la riproducibilità della ricerca scientifica.
La proposta di Lakens funzionerebbe solo se gli editori di riviste e le agenzie di finanziamento concordassero in anticipo di pubblicare rapporti di esperimenti che non sono stati condotti in base a criteri imposti dagli stessi scienziati. Penso che questo sia improbabile che accada in qualsiasi momento nel prossimo futuro.
Fino a quando non lo fa, Ti consiglio di non fidarti delle affermazioni di studi scientifici basati su valori di p vicino a 0,05. Insistere su uno standard più elevato.
Questo articolo è stato originariamente pubblicato su The Conversation. Leggi l'articolo originale.