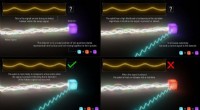
Una vista dell'interfaccia che Hosseini e il suo team hanno usato per testare il loro modello, porre ai lavoratori in crowdsourcing domande sulla geografia, film e opere d'arte tra cui scegliere, Per esempio, quale film da una selezione di quattro ha avuto i maggiori incassi al botteghino di tutti i tempi. I ricercatori hanno utilizzato sei diversi formati per suscitare risposte dai partecipanti, come selezionare la prima risposta da un elenco di quattro scelte (come mostrato nell'Attività 2) o classificare queste quattro scelte in ordine (come mostrato nell'Attività 8). Ad alcuni partecipanti è stato anche chiesto di prevedere quale risposta migliore avrebbero scelto gli altri o come gli altri avrebbero classificato il loro ordine, come mostrato in entrambi gli esempi. Credito:Pennsylvania State University
Immagina che ti venga chiesto di classificare le contee della Pennsylvania in termini di numero di infezioni da COVID-19. Oppure ti potrebbe essere chiesto di classificare le seguenti città della Pennsylvania in base alla loro popolazione:Harrisburg, Allentown, Erie e State College.
Quale sarebbe la tua risposta? Come pensi che gli altri risponderebbero a queste domande?
Un nuovo algoritmo sviluppato da un team di ricercatori guidati da Hadi Hosseini, professore assistente presso il Penn State College of Information Sciences and Technology, può raggiungere la vera risposta a questa ea domande simili combinando il voto o l'opinione di un rispondente con la sua previsione su come risponderanno gli altri.
Hosseini ha spiegato che una persona che conosce la Pennsylvania molto probabilmente conoscerà la risposta alla domanda di cui sopra. Possono anche prevedere che altri partecipanti meno informati, in media, fornirebbe la classifica errata. Al contrario, i partecipanti in uniforme molto probabilmente non sono a conoscenza della risposta corretta e possono dare una classifica errata di queste città.
"Questo è il punto cruciale del nostro algoritmo:utilizzare le informazioni extra che i partecipanti informati devono correggere per tali errori, " Egli ha detto.
Il metodo dei ricercatori si espande su un approccio esistente di sollecitare la saggezza di una folla, chiamato metodo sorprendentemente popolare, che è stato utilizzato in scenari come sondaggisti politici che prevedono l'esito delle elezioni e ricercatori che prevedono i vincitori dei giochi NFL. Come il modello di Hosseini, metodo sorprendentemente popolare chiede agli intervistati di fornire due risposte per domanda:qual è la propria opinione o voto, e come prevedono che gli altri voteranno. La tecnica sfrutta la conoscenza di un piccolo gruppo di esperti in una folla più ampia per indicare la risposta corretta.
Però, il metodo sorprendentemente popolare è stato limitato a prevedere una singola risposta corretta a una domanda posta, come "Qual è la capitale della Pennsylvania?" o "Quanti soldi ha guadagnato il film "Titanic" al botteghino di tutto il mondo?" Il modello di Hosseini estende questo concetto a scelte classificate o alternative.
"Non è necessario ottenere completamente classifiche e previsioni complete degli altri, " ha detto Hosseini. "Siamo in grado di recuperare la verità fondamentale combinando sia il voto che le previsioni senza suscitare distribuzioni complete su tutti i possibili n! classifiche. E questo vale per recuperare o solo la prima scelta o la classifica completa".
Il metodo potrebbe essere potenzialmente applicato per migliorare le previsioni con scelte classificate, come negli exit poll per prevedere i risultati delle elezioni politiche. Secondo Hosseini, ponendo agli elettori domande secondarie attraverso il suo metodo, sarebbero necessari meno campioni rispetto agli exit poll standard che si basano su un campionamento casuale.
L'approccio di Hosseini supera significativamente anche i metodi di voto convenzionali, come la regola della maggioranza semplice, che non chiedono agli intervistati di prevedere come risponderanno gli altri.
"Si scopre che la previsione dei voti degli altri è più importante dei voti effettivi, " Ha detto Hosseini. "Questo è molto cruciale perché postula che chiedere cosa pensi dell'opinione degli altri è una domanda più critica che chiedere la propria opinione".
Per testare il loro modello, Hosseini e il suo team hanno posto a 720 lavoratori in crowdsourcing domande sulla geografia, film e opere d'arte tra cui scegliere, Per esempio, quale film da una selezione di quattro ha il maggior incasso, incassi al botteghino di sempre. I ricercatori hanno utilizzato sei diversi formati per suscitare risposte dai partecipanti, come selezionare la risposta migliore da un elenco di quattro scelte o classificare queste quattro scelte in ordine. Ad alcuni partecipanti è stato anche chiesto di prevedere quale risposta migliore avrebbero scelto gli altri o come gli altri avrebbero classificato il loro ordine.
"I nostri metodi e risultati algoritmici possono avere un impatto significativo su come vediamo e affrontiamo le elezioni, sia a livello nazionale che locale, " disse Hosseini. "Ancora più importante, la nostra tecnica mostra che possiamo prevedere una classifica di verità di base con elevata precisione senza la necessità di una massiccia raccolta di dati".
Inoltre, Egli ha detto, il metodo potrebbe essere applicato in aree al di fuori della previsione dei risultati oggettivi di eventi come le elezioni politiche e le partite sportive.
"Sorprendentemente, questa tecnica funziona anche per prevedere la classifica dei prezzi dei quadri astratti, che in genere è più difficile da speculare dalla folla, " Ha aggiunto.
Hanno presentato la loro carta, "Il voto sorprendentemente popolare recupera le classifiche, Sorprendentemente!" questa settimana alla Conferenza congiunta internazionale sull'intelligenza artificiale (IJCAI-21), tenutasi virtualmente dal 19 al 26 agosto. Il lavoro è stato parzialmente finanziato dalla National Science Foundation.