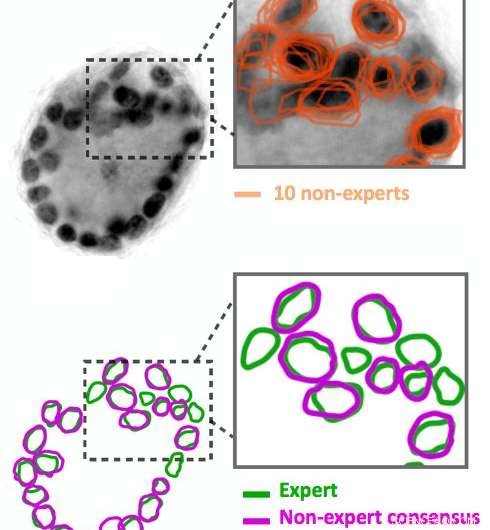
Le annotazioni dell'immagine non esperte sono rumorose. Dieci non esperti hanno delineato i cerchi neri scuri nell'immagine, che sono nuclei cellulari. I loro risultati (mostrati in arancione) non corrispondono esattamente. I nostri algoritmi sono in grado di dedurre uno schema di consenso (mostrato in viola) dai dati rumorosi. Confronta questo consenso con l'annotazione esperta della stessa immagine (mostrata in verde). Credito:IBM
Oggi il mio team IBM e i miei colleghi del laboratorio UCSF Gartner hanno riferito in Metodi della natura un approccio innovativo per generare set di dati da non esperti e utilizzarli per la formazione nell'apprendimento automatico. Il nostro approccio è progettato per consentire ai sistemi di intelligenza artificiale di apprendere altrettanto bene dai non esperti quanto dai dati di formazione generati dagli esperti. Abbiamo sviluppato una piattaforma, chiamato Quanti.us, che consente ai non esperti di analizzare le immagini (un compito comune nella ricerca biomedica) e creare un set di dati annotato. La piattaforma è completata da una serie di algoritmi studiati appositamente per interpretare correttamente questo tipo di dati "rumorosi" e incompleti. Usato insieme, queste tecnologie possono espandere le applicazioni dell'apprendimento automatico nella ricerca biomedica.
Dati non esperti e rumorosi
La disponibilità limitata di set di dati annotati di alta qualità è un collo di bottiglia nel progresso dell'apprendimento automatico. Creando algoritmi in grado di fornire risultati accurati da annotazioni di qualità inferiore e un sistema per raccogliere rapidamente tali dati, possiamo contribuire ad alleviare il collo di bottiglia. L'analisi delle immagini per le caratteristiche di interesse è un ottimo esempio. L'annotazione dell'immagine esperta è accurata ma richiede tempo, e le tecniche di analisi automatizzate come la segmentazione basata sul contrasto e il rilevamento dei bordi funzionano bene in condizioni definite ma sono sensibili ai cambiamenti nella configurazione sperimentale e possono produrre risultati inaffidabili.
Entra nel crowdsourcing. Utilizzando Quanti.us, abbiamo ottenuto annotazioni di immagini di crowdsourcing 10-50 volte più velocemente di quanto avrebbe impiegato un singolo esperto per analizzare le stesse immagini. Ma, come ci si potrebbe aspettare, le annotazioni dei non esperti erano rumorose:alcune identificavano correttamente una caratteristica e altre erano fuori bersaglio. Abbiamo sviluppato algoritmi per elaborare i dati rumorosi, dedurre la posizione corretta di un elemento dall'aggregazione di hit sia on- che off-target. Quando abbiamo addestrato una rete di regressione convoluzionale profonda utilizzando il set di dati crowd-sourced, ha funzionato quasi come una rete formata su annotazioni esperte, rispetto alla precisione e al richiamo. Insieme al documento che descrive il nostro approccio e la nostra strategia, abbiamo rilasciato il codice sorgente per il nostro algoritmo.
Applicazioni nell'ingegneria cellulare
L'analisi delle immagini è fondamentale in molti campi della biologia quantitativa e della medicina. Alcuni anni fa noi e i nostri collaboratori abbiamo annunciato il Center for Cellular Construction (CCC), finanziato dalla NSF, un centro scientifico e tecnologico che sta aprendo la strada alla nuova disciplina scientifica dell'ingegneria cellulare. CCC facilita una stretta collaborazione tra esperti di diverse discipline, come l'apprendimento automatico, fisica, informatica, biologia cellulare e molecolare, e genomica, per guidare il progresso nell'ingegneria cellulare. Ci proponiamo di studiare e realizzare celle utilizzabili come macchine automatizzate, o sensori ad hoc, per apprendere informazioni nuove e vitali su una varietà di entità biologiche e sulla loro relazione con l'ambiente in cui vivono. Usiamo l'analisi delle immagini per individuare la posizione e le dimensioni dei componenti interni delle cellule. Ma anche con tecniche di imaging avanzate, l'esatta inferenza delle sottostrutture cellulari può essere incredibilmente rumorosa, rendendo difficile operare sui componenti della cella. La nostra tecnica può utilizzare questi dati rumorosi per prevedere correttamente dove potrebbero essere le strutture cellulari rilevanti, consentendo una migliore identificazione degli organelli coinvolti nella produzione di importanti sostanze chimiche o potenziali bersagli farmacologici in una malattia.
Riteniamo che i nostri algoritmi siano un primo passo importante verso piattaforme AI più complesse. Tali sistemi possono utilizzare ulteriori paradigmi "umani nel ciclo", coinvolgendo un biologo per correggere gli errori durante la fase di formazione, Per esempio, per migliorare ulteriormente le prestazioni. Vediamo anche un'opportunità per applicare il nostro metodo oltre la biologia ad altri campi in cui i set di dati annotati di alta qualità potrebbero essere scarsi.
Questa storia è stata ripubblicata per gentile concessione di IBM Research. Leggi la storia originale qui.














