Credito:la conversazione
Un rapporto interno di Facebook ha rilevato che gli algoritmi della piattaforma di social media - le regole seguite dai suoi computer nel decidere il contenuto che vedi - hanno consentito alle campagne di disinformazione con sede nell'Europa orientale di raggiungere quasi la metà di tutti gli americani nel periodo precedente alle elezioni presidenziali del 2020, secondo un rapporto di Technology Review.
Le campagne hanno prodotto le pagine più popolari per i contenuti cristiani e neri americani, e complessivamente ha raggiunto 140 milioni di utenti statunitensi al mese. Il settantacinque percento delle persone esposte al contenuto non aveva seguito nessuna delle pagine. Le persone hanno visto il contenuto perché il sistema di raccomandazione dei contenuti di Facebook lo ha inserito nei loro feed di notizie.
Le piattaforme di social media fanno molto affidamento sul comportamento delle persone per decidere il contenuto che vedi. In particolare, guardano i contenuti a cui le persone rispondono o "coinvolgono" mettendo mi piace, commentare e condividere. allevamenti di troll, organizzazioni che diffondono contenuti provocatori, sfruttalo copiando contenuti ad alto coinvolgimento e pubblicandoli come propri.
In qualità di scienziato informatico che studia i modi in cui un gran numero di persone interagiscono utilizzando la tecnologia, Capisco la logica dell'uso della saggezza delle folle in questi algoritmi. Vedo anche sostanziali insidie nel modo in cui le società di social media lo fanno in pratica.
Alla vigilia delle elezioni del 2020, le troll farm gestivano vaste reti di pagine su FB mirando a Christian, Nero, &Nativi americani. Un rapporto interno che traccia la situazione lo ha descritto come "genuinamente orribile". Alcune pagine rimangono due anni dopo. https://t.co/Wa43f8rG0N
— Karen Hao (@_KarenHao) 17 settembre, 2021
Dai leoni della savana ai like su Facebook
Il concetto della saggezza delle folle presuppone che usando i segnali delle azioni degli altri, opinioni e preferenze come guida condurranno a decisioni valide. Per esempio, le previsioni collettive sono normalmente più accurate di quelle individuali. L'intelligenza collettiva viene utilizzata per prevedere i mercati finanziari, gli sport, elezioni e persino epidemie.
Durante milioni di anni di evoluzione, questi principi sono stati codificati nel cervello umano sotto forma di pregiudizi cognitivi che vengono con nomi come familiarità, mera esposizione ed effetto carrozzone. Se tutti iniziano a correre, dovresti anche iniziare a correre; forse qualcuno ha visto un leone arrivare e correre potrebbe salvarti la vita. Potresti non sapere perché, ma è più saggio fare domande dopo.
Il tuo cervello raccoglie indizi dall'ambiente, compresi i tuoi coetanei, e usa semplici regole per tradurre rapidamente quei segnali in decisioni:vai con il vincitore, seguire la maggioranza, copia il tuo vicino. Queste regole funzionano molto bene in situazioni tipiche perché si basano su ipotesi valide. Per esempio, presumono che le persone spesso agiscano razionalmente, è improbabile che molti si sbaglino, il passato predice il futuro, e così via.
La tecnologia consente alle persone di accedere ai segnali da un numero molto maggiore di altre persone, la maggior parte dei quali non conoscono. Le applicazioni di intelligenza artificiale fanno un uso massiccio di questi segnali di popolarità o di "coinvolgimento", dalla selezione dei risultati dei motori di ricerca alla raccomandazione di musica e video, e dal suggerire amici alla classifica dei post sui feed di notizie.
Non tutto ciò che è virale merita di essere
La nostra ricerca mostra che praticamente tutte le piattaforme tecnologiche web, come i social media e i sistemi di raccomandazione di notizie, hanno una forte tendenza alla popolarità. Quando le applicazioni sono guidate da segnali come il coinvolgimento piuttosto che da query esplicite dei motori di ricerca, il pregiudizio di popolarità può portare a conseguenze indesiderate dannose.
Social media come Facebook, Instagram, Twitter, YouTube e TikTok fanno molto affidamento sugli algoritmi di intelligenza artificiale per classificare e consigliare i contenuti. Questi algoritmi prendono come input ciò che ti piace, commentare e condividere, in altre parole, contenuti con cui interagisci. L'obiettivo degli algoritmi è massimizzare il coinvolgimento scoprendo cosa piace alle persone e posizionandolo in cima ai loro feed.
In superficie questo sembra ragionevole. Se alla gente piacciono le notizie credibili, opinioni di esperti e video divertenti, questi algoritmi dovrebbero identificare tali contenuti di alta qualità. Ma la saggezza delle folle fa un presupposto chiave qui:che raccomandare ciò che è popolare aiuterà i contenuti di alta qualità a "far bollire".
Abbiamo testato questa ipotesi studiando un algoritmo che classifica gli elementi utilizzando un mix di qualità e popolarità. Abbiamo scoperto che in generale, è più probabile che il bias di popolarità riduca la qualità complessiva del contenuto. Il motivo è che il coinvolgimento non è un indicatore affidabile di qualità quando poche persone sono state esposte a un oggetto. In questi casi, impegno genera un segnale rumoroso, ed è probabile che l'algoritmo amplifichi questo rumore iniziale. Una volta che la popolarità di un articolo di bassa qualità è abbastanza grande, continuerà ad essere amplificato.
Gli algoritmi non sono l'unica cosa influenzata dal bias di coinvolgimento:possono influenzare anche le persone. Le prove mostrano che le informazioni vengono trasmesse tramite "contagio complesso, " significa più volte le persone sono esposte a un'idea online, più è probabile che lo adottino e lo ricondividano. Quando i social media dicono alle persone che un articolo sta diventando virale, i loro pregiudizi cognitivi entrano in gioco e si traducono nell'irresistibile bisogno di prestare attenzione e condividerlo.
Folle non così sagge
Di recente abbiamo condotto un esperimento utilizzando un'app di alfabetizzazione alle notizie chiamata Fakey. È un gioco sviluppato dal nostro laboratorio, che simula un feed di notizie come quelli di Facebook e Twitter. I giocatori vedono un mix di articoli attuali da notizie false, scienza spazzatura, fonti iperpartigiane e cospirative, così come le fonti principali. Ottengono punti per la condivisione o il gradimento di notizie da fonti affidabili e per la segnalazione di articoli a bassa credibilità per il controllo dei fatti.
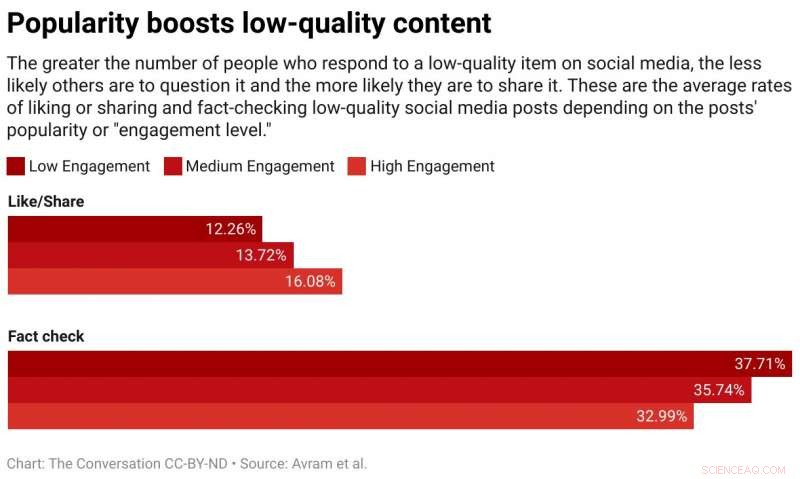
Abbiamo scoperto che è più probabile che i giocatori apprezzino o condividano e meno probabilità di segnalare articoli da fonti a bassa credibilità quando i giocatori possono vedere che molti altri utenti hanno interagito con quegli articoli. L'esposizione alle metriche di coinvolgimento crea quindi una vulnerabilità.
La saggezza delle folle fallisce perché è costruita sul falso presupposto che la folla sia composta da diversi, fonti indipendenti. Ci possono essere diversi motivi per cui questo non è il caso.
Primo, a causa della tendenza delle persone ad associarsi con persone simili, i loro quartieri online non sono molto diversi. La facilità con cui gli utenti dei social media possono rimuovere gli amici da coloro con cui non sono d'accordo spinge le persone in comunità omogenee, spesso chiamate camere d'eco.
Secondo, perché gli amici di molte persone sono amici gli uni degli altri, si influenzano a vicenda. Un famoso esperimento ha dimostrato che sapere quale musica piace ai tuoi amici influisce sulle tue preferenze dichiarate. Il tuo desiderio sociale di conformarti distorce il tuo giudizio indipendente.
Terzo, segnali di popolarità possono essere giocati. Negli anni, i motori di ricerca hanno sviluppato tecniche sofisticate per contrastare le cosiddette "link farm" e altri schemi per manipolare gli algoritmi di ricerca. Piattaforme di social media, d'altra parte, stanno appena iniziando a conoscere le proprie vulnerabilità.
Le persone che mirano a manipolare il mercato dell'informazione hanno creato account falsi, come troll e social bot, e reti false organizzate. Hanno inondato la rete per creare l'impressione che una teoria del complotto o un candidato politico sia popolare, ingannando contemporaneamente sia gli algoritmi della piattaforma che i pregiudizi cognitivi delle persone. Hanno persino alterato la struttura dei social network per creare illusioni sulle opinioni della maggioranza.
Ridurre l'impegno
Cosa fare? Le piattaforme tecnologiche sono attualmente sulla difensiva. Stanno diventando più aggressivi durante le elezioni nel rimuovere account falsi e disinformazione dannosa. Ma questi sforzi possono essere simili a un gioco di whack-a-mole.
Un diverso, approccio preventivo sarebbe quello di aggiungere attrito. In altre parole, rallentare il processo di diffusione delle informazioni. Comportamenti ad alta frequenza come il gradimento automatico e la condivisione potrebbero essere inibiti da test o commissioni CAPTCHA. Questo non solo diminuirebbe le opportunità di manipolazione, ma con meno informazioni le persone sarebbero in grado di prestare maggiore attenzione a ciò che vedono. Lascerebbe meno spazio ai pregiudizi di coinvolgimento per influenzare le decisioni delle persone.
Sarebbe anche utile se le società di social media modificassero i loro algoritmi per fare meno affidamento sul coinvolgimento per determinare i contenuti che ti servono. Forse le rivelazioni sulla conoscenza di Facebook delle fattorie di troll che sfruttano il coinvolgimento forniranno l'impulso necessario.
Questo articolo è stato ripubblicato da The Conversation con una licenza Creative Commons. Leggi l'articolo originale.