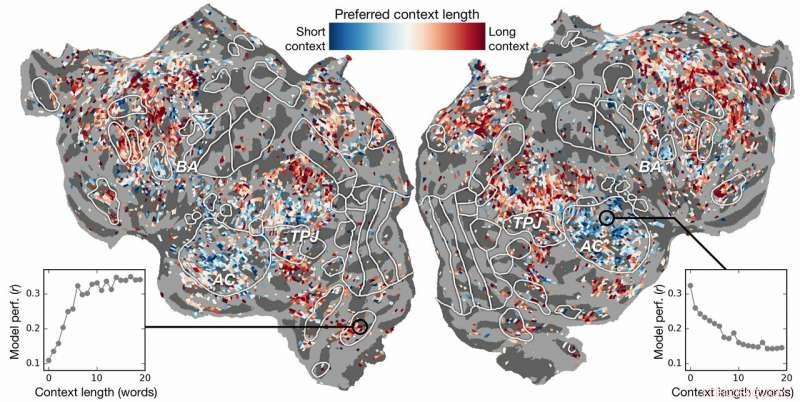
Preferenza della lunghezza del contesto attraverso la corteccia. Viene calcolato un indice di preferenza della lunghezza del contesto per ogni voxel in un soggetto e proiettato sulla superficie corticale di quel soggetto. I voxel mostrati in blu sono meglio modellati usando un contesto breve, mentre i voxel rossi sono meglio modellati con un contesto lungo. Credito:laboratorio Huth, UT Austin
L'intelligenza artificiale (AI) può aiutarci a capire come il cervello comprende il linguaggio? Le neuroscienze possono aiutarci a capire perché l'intelligenza artificiale e le reti neurali sono efficaci nel prevedere la percezione umana?
La ricerca di Alexander Huth e Shailee Jain dell'Università del Texas ad Austin (UT Austin) suggerisce che entrambi sono possibili.
In un documento presentato alla Conferenza 2018 sui sistemi di elaborazione delle informazioni neurali (NeurIPS), gli studiosi hanno descritto i risultati di esperimenti che hanno utilizzato reti neurali artificiali per prevedere con maggiore precisione che mai come le diverse aree del cervello rispondono a parole specifiche.
"Mentre le parole entrano nella nostra testa, ci formiamo idee su ciò che qualcuno ci sta dicendo, e vogliamo capire come ci arriva dentro il cervello, " disse Huth, assistente professore di Neuroscienze e Informatica presso UT Austin. "Sembra che dovrebbero esserci dei sistemi, ma praticamente, non è così che funziona il linguaggio. Come qualsiasi cosa in biologia, è molto difficile da ridurre a un semplice insieme di equazioni."
Il lavoro ha impiegato un tipo di rete neurale ricorrente chiamata memoria a lungo termine (LSTM) che include nei suoi calcoli le relazioni di ogni parola con ciò che è venuto prima per preservare meglio il contesto.
"Se una parola ha più significati, si deduce il significato di quella parola per quella particolare frase a seconda di quanto detto prima, " ha detto Giain, un dottorato di ricerca studente nel laboratorio di Huth alla UT Austin. "La nostra ipotesi è che ciò porterebbe a migliori previsioni dell'attività cerebrale perché il cervello si preoccupa del contesto".
Sembra ovvio, ma per decenni gli esperimenti di neuroscienza hanno considerato la risposta del cervello alle singole parole senza un senso della loro connessione a catene di parole o frasi. (Huth descrive l'importanza di fare "neuroscienze del mondo reale" in un articolo di marzo 2019 nel Journal of Cognitive Neuroscience .)
Nel loro lavoro, i ricercatori hanno condotto esperimenti per testare, e alla fine prevedere, come le diverse aree del cervello risponderebbero quando si ascoltano storie (in particolare, l'ora radiofonica della falena). Hanno usato i dati raccolti dalle macchine fMRI (risonanza magnetica funzionale) che catturano i cambiamenti nel livello di ossigenazione del sangue nel cervello in base a quanto sono attivi i gruppi di neuroni. Questo serve come corrispondente per dove i concetti linguistici sono "rappresentati" nel cervello.
Utilizzando potenti supercomputer presso il Texas Advanced Computing Center (TACC), hanno addestrato un modello linguistico utilizzando il metodo LSTM in modo che potesse prevedere efficacemente quale parola sarebbe venuta dopo, un'attività simile alle ricerche di completamento automatico di Google, cui la mente umana è particolarmente abile.
"Nel cercare di prevedere la prossima parola, questo modello deve implicitamente imparare tutte queste altre cose su come funziona il linguaggio, " disse Huth, "come quali parole tendono a seguire altre parole, senza mai accedere effettivamente al cervello o ad alcun dato sul cervello."
Sulla base sia del modello linguistico che dei dati fMRI, hanno addestrato un sistema in grado di prevedere come il cervello avrebbe risposto quando ascoltava per la prima volta ogni parola in una nuova storia.
Gli sforzi passati avevano dimostrato che è possibile localizzare efficacemente le risposte linguistiche nel cervello. Però, la nuova ricerca ha mostrato che l'aggiunta dell'elemento contestuale, in questo caso fino a 20 parole precedenti, ha migliorato significativamente le previsioni sull'attività cerebrale. Hanno scoperto che le loro previsioni migliorano anche quando è stata utilizzata la minor quantità di contesto. Il contesto più fornito, migliore è l'accuratezza delle loro previsioni.
"La nostra analisi ha mostrato che se l'LSTM incorpora più parole, poi migliora nel predire la parola successiva, " ha detto Giain, "il che significa che deve includere informazioni da tutte le parole del passato."
La ricerca è andata oltre. Ha esplorato quali parti del cervello erano più sensibili alla quantità di contesto inclusa. Hanno trovato, ad esempio, che i concetti che sembrano essere localizzati nella corteccia uditiva erano meno dipendenti dal contesto.
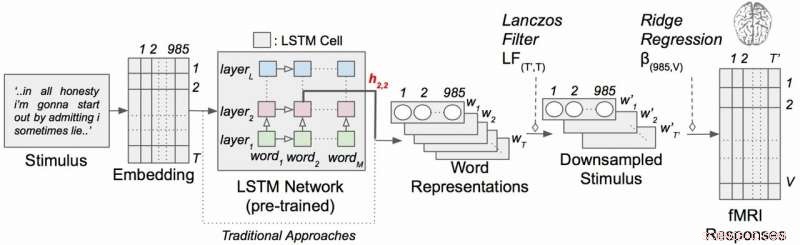
Modello di codifica del linguaggio contestuale con stimoli narrativi. Ogni parola della storia viene prima proiettata in uno spazio di inclusione a 985 dimensioni. Le sequenze di rappresentazioni di parole vengono quindi inserite in una rete LSTM che è stata pre-addestrata come modello linguistico. Credito:laboratorio Huth, UT Austin
"Se senti la parola cane, a quest'area non importa quali fossero le 10 parole prima, risponderà solo al suono della parola cane", Huth ha spiegato.
D'altra parte, le aree del cervello che si occupano del pensiero di livello superiore erano più facili da individuare quando veniva incluso più contesto. Questo supporta le teorie della mente e della comprensione del linguaggio.
"C'era davvero una bella corrispondenza tra la gerarchia della rete artificiale e la gerarchia del cervello, che abbiamo trovato interessante, "ha detto Huth.
L'elaborazione del linguaggio naturale, o PNL, ha fatto passi da gigante negli ultimi anni. Ma quando si tratta di rispondere alle domande, avere conversazioni naturali, o analizzando i sentimenti nei testi scritti, La PNL ha ancora molta strada da fare. I ricercatori ritengono che il loro modello linguistico sviluppato da LSTM possa aiutare in queste aree.
L'LSTM (e le reti neurali in generale) funziona assegnando valori nello spazio ad alta dimensione ai singoli componenti (qui, parole) in modo che ogni componente possa essere definito dalle sue migliaia di relazioni disparate con molte altre cose.
I ricercatori hanno addestrato il modello linguistico alimentandolo con decine di milioni di parole tratte dai post di Reddit. Il loro sistema ha quindi fatto previsioni su come migliaia di voxel (pixel tridimensionali) nel cervello di sei soggetti avrebbero risposto a una seconda serie di storie che né il modello né gli individui avevano sentito prima. Poiché erano interessati agli effetti della lunghezza del contesto e all'effetto dei singoli strati nella rete neurale, hanno essenzialmente testato 60 diversi fattori (20 lunghezze di ritenzione del contesto e tre diverse dimensioni del livello) per ogni soggetto.
Tutto ciò porta a problemi computazionali di enorme scala, richiedono enormi quantità di potenza di calcolo, memoria, Conservazione, e recupero dati. Le risorse di TACC erano adatte al problema. I ricercatori hanno utilizzato il supercomputer Maverick, che contiene sia GPU che CPU per le attività di elaborazione, e Corral, una risorsa di archiviazione e gestione dei dati, conservare e distribuire i dati. Parallelizzando il problema su più processori, sono stati in grado di eseguire l'esperimento computazionale in settimane anziché anni.
"Per sviluppare efficacemente questi modelli, hai bisogno di molti dati di allenamento, "Ha detto Huth. "Ciò significa che devi passare attraverso l'intero set di dati ogni volta che vuoi aggiornare i pesi. E questo è intrinsecamente molto lento se non usi risorse parallele come quelle di TACC."
Se sembra complesso, bene, lo è.
Questo sta portando Huth e Jain a considerare una versione più snella del sistema, dove invece di sviluppare un modello di predizione del linguaggio e poi applicarlo al cervello, sviluppano un modello che predice direttamente la risposta del cervello. Lo chiamano un sistema end-to-end ed è lì che Huth e Jain sperano di andare nella loro ricerca futura. Un tale modello migliorerebbe le sue prestazioni direttamente sulle risposte del cervello. Una previsione errata dell'attività cerebrale darebbe un feedback al modello e stimolerebbe miglioramenti.
"Se funziona, allora è possibile che questa rete possa imparare a leggere il testo o ad assimilare il linguaggio in modo simile a come fa il nostro cervello, " disse Huth. "Immagina Google Translate, ma capisce quello che dici, invece di imparare solo una serie di regole."
Con un tale sistema in atto, Huth crede che sia solo questione di tempo prima che un sistema di lettura della mente in grado di tradurre l'attività cerebrale in linguaggio sia fattibile. Intanto, stanno acquisendo informazioni sia sulle neuroscienze che sull'intelligenza artificiale dai loro esperimenti.
"Il cervello è una macchina di calcolo molto efficace e lo scopo dell'intelligenza artificiale è costruire macchine che siano davvero brave in tutti i compiti che un cervello può svolgere, " Jain ha detto. "Ma, non capiamo molto del cervello. Così, cerchiamo di usare l'intelligenza artificiale per prima chiederci come funziona il cervello, poi, sulla base delle intuizioni che otteniamo attraverso questo metodo di interrogatorio, e attraverso le neuroscienze teoriche, usiamo questi risultati per sviluppare una migliore intelligenza artificiale.
"L'idea è di comprendere i sistemi cognitivi, sia biologico che artificiale, e usarli in tandem per capire e costruire macchine migliori."