Credito:Nvidia
L'obiettivo:trasformare le immagini 2D in modelli 3D utilizzando una speciale architettura di codificatore-decodificatore. Gli attori:Nvidia. L'elogio:un utilizzo intelligente dell'apprendimento automatico con utili applicazioni del mondo reale.
Paul Lilly in Hardware caldo è stato tra gli osservatori tecnologici che hanno notato che il modo in cui sono passati dal 2D al 3D era una novità. Non è una grande sorpresa quando il percorso è il contrario, dal 3D al 2D, ma "creare un modello 3D senza alimentare un sistema di dati 3D è molto più impegnativo".
Lilly ha citato Jun Gao, uno dei team di ricerca che ha lavorato sull'approccio di rendering. "Questa è essenzialmente la prima volta in assoluto che puoi prendere qualsiasi immagine 2-D e prevedere proprietà 3-D rilevanti."
La loro salsa magica nel produrre un oggetto 3-D da immagini 2-D è un "renderer differenziabile basato sull'interpolazione, " o DIB-R. I ricercatori di Nvidia hanno addestrato il loro modello su set di dati che includevano immagini di uccelli. Dopo l'addestramento, DIB-R aveva la capacità di prendere un'immagine di un uccello e fornire una rappresentazione 3D, con la giusta forma e consistenza di un uccello 3-D.
Nvidia ha ulteriormente descritto l'input trasformato in una mappa delle caratteristiche o in un vettore che viene utilizzato per prevedere informazioni specifiche come forma, colore, trama e illuminazione di un'immagine.
Perché questo è importante: Gizmodo il titolo lo riassumeva. "Nvidia ha insegnato a un'intelligenza artificiale a generare istantaneamente modelli 3D completamente strutturati da immagini 2D piatte." Quella parola "istantaneamente" è importante.
DIB-R può produrre un oggetto 3-D da un'immagine 2-D in meno di 100 millisecondi, ha detto Lauren Finkle di Nvidia. "Lo fa alterando una sfera poligonale, il modello tradizionale che rappresenta una forma 3D. DIB-R lo altera per adattarlo alla forma dell'oggetto reale ritratta nelle immagini 2D".
Andrew Liszewski in Gizmodo ha evidenziato questo elemento temporale di 100 millisecondi. "Quella impressionante velocità di elaborazione è ciò che rende questo strumento particolarmente interessante perché ha il potenziale per migliorare notevolmente il modo in cui macchine come i robot, o auto autonome, vedere il mondo, e capire cosa li attende".
Per quanto riguarda le auto a guida autonoma, Liszewski ha detto, "Le immagini fisse estratte da un flusso video in diretta da una telecamera potrebbero essere convertite istantaneamente in modelli 3D che consentono un'auto autonoma, Per esempio, per misurare con precisione le dimensioni di un camion di grandi dimensioni che deve evitare."

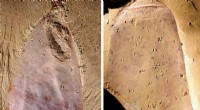
Il team ha testato DIB-R su quattro immagini 2D di uccelli (all'estrema sinistra). Il primo esperimento ha utilizzato l'immagine di una silvia gialla (in alto a sinistra) e ha prodotto un oggetto 3D (due righe in alto). Credito:Nvidia
Un modello in grado di dedurre un oggetto 3D da un'immagine 2D sarebbe in grado di eseguire un migliore tracciamento dell'oggetto, e Lilly si è dedicata al suo utilizzo nella robotica. "Elaborando immagini 2D in modelli 3D, un robot autonomo sarebbe in una posizione migliore per interagire con il suo ambiente in modo più sicuro ed efficiente, " Egli ha detto.
Nvidia ha notato che i robot autonomi, per farlo, "deve essere in grado di percepire e comprendere l'ambiente circostante. DIB-R potrebbe potenzialmente migliorare quelle capacità di percezione della profondità".
Gizmodo di Liszewski, nel frattempo, ha menzionato cosa potrebbe fare l'approccio Nvidia per la sicurezza. "DIB-R potrebbe persino migliorare le prestazioni delle telecamere di sicurezza incaricate di identificare le persone e rintracciarle, poiché un modello 3D generato istantaneamente renderebbe più facile eseguire corrispondenze di immagini mentre una persona si muove attraverso il suo campo visivo."
I ricercatori Nvidia presenteranno il loro modello questo mese alla Conferenza annuale sui sistemi di elaborazione delle informazioni neurali (NeurIPS), a Vancouver.
Coloro che desiderano saperne di più sulla loro ricerca possono consultare il loro articolo su arXiv, "Imparare a prevedere oggetti 3D con un renderer differenziabile basato sull'interpolazione". Gli autori sono Wenzheng Chen, Jun Gao, Huan Ling, Edward J. Smith, Jaakko Lehtinen, Alec Jacobson e Sanja Fidler.
Hanno proposto "un renderer differenziabile completo basato sulla rasterizzazione per il quale i gradienti possono essere calcolati analiticamente". Quando avvolto attorno a una rete neurale, la loro struttura ha imparato a prevedere la forma, struttura, e luce da singole immagini, loro hanno detto, e hanno mostrato la loro struttura "per imparare un generatore di forme strutturate 3D".
Nel loro astratto, gli autori hanno osservato che "Molti modelli di apprendimento automatico operano su immagini, ma ignora il fatto che le immagini sono proiezioni 2-D formate da geometrie 3-D che interagiscono con la luce, in un processo chiamato rendering. Consentire ai modelli ML di comprendere la formazione delle immagini potrebbe essere la chiave per la generalizzazione".
Hanno presentato DIB-R come una struttura che consente di calcolare analiticamente i gradienti per tutti i pixel di un'immagine.
Hanno affermato che la chiave del loro approccio era "vedere la rasterizzazione in primo piano come un'interpolazione ponderata delle proprietà locali e la rasterizzazione in background come un'aggregazione basata sulla distanza della geometria globale. Il nostro approccio consente un'ottimizzazione accurata sulle posizioni dei vertici, colori, normali, le direzioni della luce e le coordinate delle texture attraverso una varietà di modelli di illuminazione."
© 2019 Science X Network